Usage and Examples
Before use
Attention
- By default, csvtk assumes input files have header row, if not, switch flag
-Hon. - By default, csvtk handles CSV files, use flag
-tfor tab-delimited files. - Column names should be unique.
- By default, lines starting with
#will be ignored, if the header row starts with#, please assign flag-Canother rare symbol, e.g.$. - Do not mix use field (column) numbers and names to specify columns to operate.
- The CSV parser requires all the lines have same numbers of fields/columns.
Even lines with spaces will cause error.
Use
-I/--ignore-illegal-rowto skip these lines if neccessary. You can also use "csvtk fix" to fix files with different numbers of columns in rows. -
If double-quotes exist in fields not enclosed with double-quotes, e.g.,
x,a "b" c,1It would report error:
bare `"` in non-quoted-field.Please switch on the flag
-lor usecsvtk fix-quotesto fix it. -
If somes fields have only a double-quote eighter in the beginning or in the end, e.g.,
x,d "e","a" b c,1It would report error:
extraneous or missing " in quoted-fieldPlease use
csvtk fix-quotesto fix it, and usecsvtk del-quotesto reset to the original format as needed. -
csvtk writes gzip files very fast, much faster than the multi-threaded pigz, therefore there's no need to pipe the result to gzip/pigz. csvtk also supports reading and writing xz (.xz), zstd (.zst) and Bzip2 (.bz2) formats.
-
Less than half of the subcommands support >1 file.
Table of Contents
Information
Format conversion
Set operations
Edit
- add-header
- comma
- del-quotes
- del-header
- fix
- fix-quotes
- fmtdate
- mutate
- mutate2
- mutate3
- rename
- rename2
- replace
- round
Transform
Ordering
Ploting
Misc
csvtk
Usage
csvtk -- a cross-platform, efficient and practical CSV/TSV toolkit
Version: 0.37.0
Author: Wei Shen <shenwei356@gmail.com>
Documents : http://shenwei356.github.io/csvtk
Source code: https://github.com/shenwei356/csvtk
Attention:
1. By default, csvtk assumes input files have header row, if not, switch flag "-H" on.
2. By default, csvtk handles CSV files, use flag "-t" for tab-delimited files.
3. Column names should be unique.
4. By default, lines starting with "#" will be ignored, if the header row
starts with "#", please assign flag "-C" another rare symbol, e.g. '$'.
5. Do not mix use field (column) numbers and names to specify columns to operate.
6. The CSV parser requires all the lines have same numbers of fields/columns.
Even lines with spaces will cause error.
Use '-I/--ignore-illegal-row' to skip these lines if neccessary.
You can also use "csvtk fix" to fix files with different numbers of columns in rows.
7. If double-quotes exist in fields not enclosed with double-quotes, e.g.,
x,a "b" c,1
It would report error:
bare " in non-quoted-field.
Please switch on the flag "-l" or use "csvtk fix-quotes" to fix it.
8. If somes fields have only a double-quote eighter in the beginning or in the end, e.g.,
x,d "e","a" b c,1
It would report error:
extraneous or missing " in quoted-field
Please use "csvtk fix-quotes" to fix it, and use "csvtk del-quotes" to reset to the
original format as needed.
9. csvtk writes gzip files very fast, much faster than the multi-threaded pigz,
therefore there's no need to pipe the result to gzip/pigz.
csvtk also supports reading and writing xz (.xz), zstd (.zst) and Bzip2 (.bz2) formats.
10. Less than half of the subcommands support >1 file.
Environment variables for frequently used global flags:
- "CSVTK_T" for flag "-t/--tabs"
- "CSVTK_H" for flag "-H/--no-header-row"
- "CSVTK_QUIET" for flag "--quiet"
You can also create a symbolic link named "tsvtk" to csvtk, or simply create a copy
of the executable called "tsvtk". When invoked as "tsvtk", csvtk will automatically
enable the "-t/--tabs" flag.
Usage:
csvtk [flags]
csvtk [command]
Commands for Information:
corr calculate Pearson correlation between two columns
dim dimensions of CSV file
headers print headers
ncol print number of columns
nrow print number of records
summary summary statistics of selected numeric or text fields (groupby group fields)
watch monitor the specified fields
Format Conversion:
csv2json convert CSV to JSON format
csv2md convert CSV to markdown format
csv2rst convert CSV to reStructuredText format
csv2tab convert CSV to tabular format
csv2xlsx convert CSV/TSV files to XLSX file
pretty convert CSV to a readable aligned table
space2tab convert space delimited format to TSV
splitxlsx split XLSX sheet into multiple sheets according to column values
tab2csv convert tabular format to CSV
xlsx2csv convert XLSX to CSV format
Commands for Set Operation:
comb compute combinations of items at every row
concat concatenate CSV/TSV files by rows
cut select and arrange fields
filter filter rows by values of selected fields with arithmetic expression
filter2 filter rows by awk-like arithmetic/string expressions
freq frequencies of selected fields
grep grep data by selected fields with patterns/regular expressions
head print first N records
inter intersection of multiple files
join join files by selected fields (inner, left and outer join)
sample sampling by proportion
split split CSV/TSV into multiple files according to column values
uniq unique data without sorting
Commands for Edit:
add-header add column names
comma make numbers more readable by adding commas
del-header delete column names
del-quotes remove extra double quotes added by 'fix-quotes'
fix fix CSV/TSV with different numbers of columns in rows
fix-quotes fix malformed CSV/TSV caused by double-quotes
fmtdate format date of selected fields
mutate create new column from selected fields by regular expression
mutate2 create a new column from selected fields by awk-like arithmetic/string expressions
mutate3 create a new column from selected fields with Go-like expressions
rename rename column names with new names
rename2 rename column names by regular expression
replace replace data of selected fields by regular expression
round round float to n decimal places
Commands for Data Transformation:
fold fold multiple values of a field into cells of groups
gather gather columns into key-value pairs, like tidyr::gather/pivot_longer
sep separate column into multiple columns
spread spread a key-value pair across multiple columns, like tidyr::spread/pivot_wider
transpose transpose CSV data
unfold unfold multiple values in cells of a field
Commands for Ordering:
shuf shuffle rows
sort sort by selected fields
Commands for Ploting:
plot plot common figures
Commands for Miscellaneous Functions:
cat stream file to stdout and report progress on stderr
Additional Commands:
genautocomplete generate shell autocompletion script (bash|zsh|fish|powershell)
version print version information and check for update
Flags:
-C, --comment-char string lines starting with commment-character will be ignored. if your header
row starts with '#', please assign "-C" another rare symbol, e.g. '$'
(default "#")
-U, --delete-header do not output header row
-d, --delimiter string delimiting character of the input CSV file (default ",")
-h, --help help for csvtk
-E, --ignore-empty-row ignore empty rows
-I, --ignore-illegal-row ignore illegal rows. You can also use 'csvtk fix' to fix files with
different numbers of columns in rows
-X, --infile-list string file of input files list (one file per line), if given, they are appended
to files from cli arguments. Note that less than half of the subcommands
support >1 file.
-l, --lazy-quotes if given, a quote may appear in an unquoted field and a non-doubled quote
may appear in a quoted field
-H, --no-header-row specifies that the input CSV file does not have header row
-j, --num-cpus int number of CPUs to use (default 4)
-D, --out-delimiter string delimiting character of the output CSV file, e.g., -D $'\t' for tab
(default ",")
-o, --out-file string out file ("-" for stdout, suffix .gz for gzipped out) (default "-")
-T, --out-tabs specifies that the output is delimited with tabs. Overrides "-D"
--quiet be quiet and do not show extra information and warnings
-Z, --show-row-number show row number as the first column, with header row skipped
-t, --tabs specifies that the input CSV file is delimited with tabs. Overrides "-d"
-V, --version print version information
Use "csvtk [command] --help" for more information about a command.
add-header
Usage
add column names
Usage:
csvtk add-header [flags]
Flags:
-h, --help help for add-header
-n, --names strings column names to add, in CSV format
Examples:
-
No new colnames given:
$ seq 3 | csvtk mutate -H \ | csvtk add-header [WARN] colnames not given, c1, c2, c3... will be used c1,c2 1,1 2,2 3,3 -
Adding new colnames:
$ seq 3 | csvtk mutate -H \ | csvtk add-header -n a,b a,b 1,1 2,2 3,3 $ seq 3 | csvtk mutate -H \ | csvtk add-header -n a -n b a,b 1,1 2,2 3,3 $ seq 3 | csvtk mutate -H -t \ | csvtk add-header -t -n a,b a b 1 1 2 2 3 3
cat
Usage
stream file to stdout and report progress on stderr
Usage:
csvtk cat [flags]
Flags:
-b, --buffsize int buffer size (default 8192)
-h, --help help for cat
-L, --lines count lines instead of bytes
-p, --print-freq int print frequency (-1 for print after parsing) (default 1)
-s, --total int expected total bytes/lines (default -1)
Examples
-
Stream file, report progress in bytes
csvtk cat file.tsv -
Stream file from stdin, report progress in lines
tac input.tsv | csvtk cat -L -s `wc -l < input.tsv` -
comb
Usage
compute combinations of items at every row
Usage:
csvtk comb [flags]
Aliases:
comb, combination
Flags:
-h, --help help for comb
-i, --ignore-case ignore-case
-S, --nat-sort sort items in natural order
-n, --number int number of items in a combination, 0 for no limit, i.e., return all combinations
(default 2)
-s, --sort sort items in a combination
Examples:
$ cat players.csv
gender,id,name
male,1,A
male,2,B
male,3,C
female,11,a
female,12,b
female,13,c
female,14,d
# put names of one group in one row
$ cat players.csv \
| csvtk collapse -f 1 -v 3 -s ';' \
| csvtk cut -f 2
name
A;B;C
a;b;c;d
# n = 2
$ cat players.csv \
| csvtk collapse -f 1 -v 3 -s ';' \
| csvtk cut -f 2 \
| csvtk comb -d ';' -n 2
A,B
A,C
B,C
a,b
a,c
b,c
a,d
b,d
c,d
# n = 3
$ cat players.csv \
| csvtk collapse -f 1 -v 3 -s ';' \
| csvtk cut -f 2 \
| csvtk comb -d ';' -n 3
A,B,C
a,b,c
a,b,d
a,c,d
b,c,d
# n = 0
$ cat players.csv \
| csvtk collapse -f 1 -v 3 -s ';' \
| csvtk cut -f 2 \
| csvtk comb -d ';' -n 0
A
B
A,B
C
A,C
B,C
A,B,C
a
b
a,b
c
a,c
b,c
a,b,c
d
a,d
b,d
a,b,d
c,d
a,c,d
b,c,d
a,b,c,d
comma
Usage
make numbers more readable by adding commas
Usage:
csvtk comma [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for comma
Example
$ echo -ne "12345\nNA\n12345.12\n1.2e6\n" \
| csvtk mutate -Ht | csvtk pretty -Ht
12345 12345
NA NA
12345.12 12345.12
1.2e6 1.2e6
$ echo -ne "12345\nNA\n12345.12\n1.2e6\n" \
| csvtk mutate -Ht \
| csvtk comma -Ht -f 1- \
| csvtk pretty -Ht
12,345 12,345
NA NA
12,345.12 12,345.12
1,200,000 1,200,000
concat
Usage
concatenate CSV/TSV files by rows
Note that the second and later files are concatenated to the first one,
so only columns match that of the first files kept.
Usage:
csvtk concat [flags]
Flags:
-h, --help help for concat
-i, --ignore-case ignore case (column name)
-k, --keep-unmatched keep blanks even if no any data of a file matches
-u, --unmatched-repl string replacement for unmatched data
Examples
-
data
$ csvtk pretty names.csv id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 $ csvtk pretty names.reorder.csv last_name username id first_name Pike rob 11 Rob Thompson ken 2 Ken Griesemer gri 4 Robert Thompson abc 1 Robert Abel 123 NA Robert $ csvtk pretty names.with-unmatched-colname.csv id2 First_name Last_name Username col 22 Rob33 Pike222 rob111 abc 44 Ken33 Thompson22 ken111 def -
simple one
$ csvtk concat names.csv names.reorder.csv \ | csvtk pretty id first_name last_name username -- ---------- --------- -------- 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 -
data with unmatched column names, and ignoring cases
$ csvtk concat names.csv names.with-unmatched-colname.csv -i \ | csvtk pretty id first_name last_name username -- ---------- ---------- -------- 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 Rob33 Pike222 rob111 Ken33 Thompson22 ken111 $ csvtk concat names.csv names.with-unmatched-colname.csv -i -u Unmached \ | csvtk pretty id first_name last_name username -------- ---------- ---------- -------- 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 Unmached Rob33 Pike222 rob111 Unmached Ken33 Thompson22 ken111 -
Sometimes data of one file does not matche any column, they are discared by default. But you can keep them using flag
-k/--keep-unmatched$ csvtk concat names.with-unmatched-colname.csv names.csv \ | csvtk pretty id2 First_name Last_name Username col --- ---------- ---------- -------- --- 22 Rob33 Pike222 rob111 abc 44 Ken33 Thompson22 ken111 def $ csvtk concat names.with-unmatched-colname.csv names.csv -k -u NA \ | csvtk pretty id2 First_name Last_name Username col --- ---------- ---------- -------- --- 22 Rob33 Pike222 rob111 abc 44 Ken33 Thompson22 ken111 def NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
corr
Usage
calculate Pearson correlation between two columns
Usage:
csvtk corr [flags]
Flags:
-f, --fields string comma separated fields
-h, --help help for corr
-i, --ignore_nan Ignore non-numeric fields to avoid returning NaN
-L, --log Calcute correlations on Log10 transformed data
-x, --pass passthrough mode (forward input to output)
Examples
- Calculate pairwise correlations between field, ignore non-numeric values
csvtk -t corr -i -f Foo,Bar input.tsv
csv2json
Usage
convert CSV to JSON format
Usage:
csvtk csv2json [flags]
Flags:
-b, --blanks do not convert "", "na", "n/a", "none", "null", "." to null
-h, --help help for csv2json
-i, --indent string indent. if given blank, output json in one line. (default " ")
-k, --key string output json as an array of objects keyed by a given field rather than as a
list. e.g -k 1 or -k columnA
-n, --parse-num strings parse numeric values for nth column, multiple values are supported and
"a"/"all" for all columns
-K, --skip-key do not put KEY in the data when using -k KEY
Examples
-
test data
$ cat testdata/data4json.csv ID,room,name,status 3,G13,Simon,true 5,103,Anna,TRUE 1e-3,2,,N/A -
default operation
$ cat testdata/data4json.csv | csvtk csv2json [ { "ID": "3", "room": "G13", "name": "Simon", "status": true }, { "ID": "5", "room": "103", "name": "Anna", "status": true }, { "ID": "1e-3", "room": "2", "name": null, "status": null } ] -
change indent
$ cat testdata/data4json.csv | csvtk csv2json -i "" [{"ID":"3","room":"G13","name":"Simon","status":true},{"ID":"5","room":"103","name":"Anna","status":true},{"ID":"1e-3","room":"2","name":null,"status":null}] -
output json as an array of objects keyed by a given filed rather than as a list.
$ cat testdata/data4json.csv | csvtk csv2json -k ID { "3": { "ID": "3", "room": "G13", "name": "Simon", "status": true }, "5": { "ID": "5", "room": "103", "name": "Anna", "status": true }, "1e-3": { "ID": "1e-3", "room": "2", "name": null, "status": null } } # do not output the key column $ cat testdata/data4json.csv | csvtk csv2json -k ID --skip-key { "3": { "room": "G13", "name": "Simon", "status": true }, "5": { "room": "103", "name": "Anna", "status": true }, "1e-3": { "room": "2", "name": null, "status": null } } -
for CSV without header row
$ cat testdata/data4json.csv | csvtk csv2json -H [ [ "ID", "room", "name", "status" ], [ "3", "G13", "Simon", true ], [ "5", "103", "Anna", true ], [ "1e-3", "2", null, null ] ] -
parse numeric values.
# cat testdata/data4json.csv | csvtk csv2json -n all # for all columns # cat testdata/data4json.csv | csvtk csv2json -n 1,2 # for multiple columns $ cat testdata/data4json.csv | csvtk csv2json -n 1 # for single column [ { "ID": 3, "room": "G13", "name": "Simon", "status": true }, { "ID": 5, "room": "103", "name": "Anna", "status": true }, { "ID": 1e-3, "room": "2", "name": null, "status": null } ] -
do not convert "", "na", "n/a", "none", "null", "." to null (just like csvjon --blanks in csvkit)
$ cat testdata/data4json.csv | csvtk csv2json --blanks [ { "ID": "3", "room": "G13", "name": "Simon", "status": true }, { "ID": "5", "room": "103", "name": "Anna", "status": true }, { "ID": "1e-3", "room": "2", "name": "", "status": "N/A" } ] -
values with
",\,\n.$ cat testdata/data4json2.csv test none "Make America ""great"" again" \nations "This is a MULTILINE string" $ csvtk csv2json testdata/data4json2.csv [ { "test": null }, { "test": "Make America \"great\" again" }, { "test": "\\nations" }, { "test": "This is a\nMULTILINE\nstring" } ]
csv2md
Usage
convert CSV to markdown format
Attention:
csv2md treats the first row as header line and requires them to be unique
Usage:
csvtk csv2md [flags]
Flags:
-a, --alignments string comma separated alignments. e.g. -a l,c,c,c or -a c (default "l")
-w, --min-width int min width (at least 3) (default 3)
Examples
-
give single alignment symbol
$ cat testdata/names.csv | csvtk csv2md -a left |id |first_name|last_name|username| |:--|:---------|:--------|:-------| |11 |Rob |Pike |rob | |2 |Ken |Thompson |ken | |4 |Robert |Griesemer|gri | |1 |Robert |Thompson |abc | |NA |Robert |Abel |123 |result:
id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 -
give alignment symbols of all fields
$ cat testdata/names.csv | csvtk csv2md -a c,l,l,l |id |first_name|last_name|username| |:-:|:---------|:--------|:-------| |11 |Rob |Pike |rob | |2 |Ken |Thompson |ken | |4 |Robert |Griesemer|gri | |1 |Robert |Thompson |abc | |NA |Robert |Abel |123 |result
|id |first_name|last_name|username| |:-:|:---------|:--------|:-------| |11 |Rob |Pike |rob | |2 |Ken |Thompson |ken | |4 |Robert |Griesemer|gri | |1 |Robert |Thompson |abc | |NA |Robert |Abel |123 |
csv2rst
Usage
convert CSV to readable aligned table
Attention:
1. row span is not supported.
Usage:
csvtk csv2rst [flags]
Flags:
-k, --cross string charactor of cross (default "+")
-s, --header string charactor of separator between header row and data rowws (default "=")
-h, --help help for csv2rst
-b, --horizontal-border string charactor of horizontal border (default "-")
-p, --padding string charactor of padding (default " ")
-B, --vertical-border string charactor of vertical border (default "|")
Example
-
With header row
$ csvtk csv2rst testdata/names.csv +----+------------+-----------+----------+ | id | first_name | last_name | username | +====+============+===========+==========+ | 11 | Rob | Pike | rob | +----+------------+-----------+----------+ | 2 | Ken | Thompson | ken | +----+------------+-----------+----------+ | 4 | Robert | Griesemer | gri | +----+------------+-----------+----------+ | 1 | Robert | Thompson | abc | +----+------------+-----------+----------+ | NA | Robert | Abel | 123 | +----+------------+-----------+----------+ -
No header row
$ csvtk csv2rst -H -t testdata/digitals.tsv +---+-------+---+ | 4 | 5 | 6 | +---+-------+---+ | 1 | 2 | 3 | +---+-------+---+ | 7 | 8 | 0 | +---+-------+---+ | 8 | 1,000 | 4 | +---+-------+---+ -
Unicode
$ cat testdata/unicode.csv | csvtk csv2rst +-------+---------+ | value | name | +=======+=========+ | 1 | 沈伟 | +-------+---------+ | 2 | 沈伟b | +-------+---------+ | 3 | 沈小伟 | +-------+---------+ | 4 | 沈小伟b | +-------+---------+ -
Misc
$ cat testdata/names.csv | head -n 1 | csvtk csv2rst +----+------------+-----------+----------+ | id | first_name | last_name | username | +====+============+===========+==========+ $ cat testdata/names.csv | head -n 1 | csvtk csv2rst -H +----+------------+-----------+----------+ | id | first_name | last_name | username | +----+------------+-----------+----------+ $ echo | csvtk csv2rst -H [ERRO] xopen: no content $ echo "a" | csvtk csv2rst -H +---+ | a | +---+ $ echo "沈伟" | csvtk csv2rst -H +------+ | 沈伟 | +------+
csv2tab
Usage
convert CSV to tabular format
Usage:
csvtk csv2tab [flags]
Flags:
-h, --help help for csv2tab
Usage
$ echo a,b,c | csvtk csv2tab
a b c
csv2xlsx
Usage
convert CSV/TSV files to XLSX file
Attention:
1. Multiple CSV/TSV files are saved as separated sheets in .xlsx file.
2. All input files should all be CSV or TSV.
3. First rows are freezed unless given '-H/--no-header-row'.
Usage:
csvtk csv2xlsx [flags]
Flags:
-f, --format-numbers save numbers in number format, instead of text
-h, --help help for csv2xlsx
Examples
-
Single input
$ csvtk csv2xlsx ../testdata/names.csv -o output.xlsx # check content $ csvtk xlsx2csv -a output.xlsx index sheet 1 Sheet1 $ csvtk xlsx2csv output.xlsx | md5sum 8e9d38a012cb02279a396a2f2dbbbca9 - $ csvtk cut -f 1- ../testdata/names.csv | md5sum 8e9d38a012cb02279a396a2f2dbbbca9 - -
Merging multiple CSV/TSV files into one .xlsx file.
$ csvtk csv2xlsx ../testdata/names*.csv -o output.xlsx $ csvtk xlsx2csv -a output.xlsx index sheet 1 names 2 names.reorder 3 names.with-unmatched-colname
cut
Usage
select and arrange fields
Examples:
1. Single column
csvtk cut -f 1
csvtk cut -f colA
2. Multiple columns (replicates allowed)
csvtk cut -f 1,3,2,1
csvtk cut -f colA,colB,colA
3. Column ranges
csvtk cut -f 1,3-5 # 1, 3, 4, 5
csvtk cut -f 3,5- # 3rd col, and 5th col to the end
csvtk cut -f 1- # for all
csvtk cut -f 2-,1 # move 1th col to the end
4. Unselect
csvtk cut -f -1,-3 # discard 1st and 3rd column
csvtk cut -f -1--3 # discard 1st to 3rd column
csvtk cut -f -2- # discard 2nd and all columns on the right.
csvtu cut -f -colA,-colB # discard colA and colB
Usage:
csvtk cut [flags]
Flags:
-m, --allow-missing-col allow missing column
-b, --blank-missing-col blank missing column, only for using column fields
-f, --fields string select only these fields. type "csvtk cut -h" for examples
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for cut
-i, --ignore-case ignore case (column name)
-u, --uniq-column deduplicate columns matched by multiple fuzzy column names
Examples
-
data:
$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" -
Select columns by column index:
csvtk cut -f 1,2$ cat testdata/names.csv \ | csvtk cut -f 1,2 id,first_name 11,Rob 2,Ken 4,Robert 1,Robert NA,Robert # select more than once $ cat testdata/names.csv \ | csvtk cut -f 1,2,2 id,first_name,first_name 11,Rob,Rob 2,Ken,Ken 4,Robert,Robert 1,Robert,Robert NA,Robert,Robert -
Select columns by column names:
csvtk cut -f first_name,username$ cat testdata/names.csv \ | csvtk cut -f first_name,username first_name,username Rob,rob Ken,ken Robert,gri Robert,abc Robert,123 # select more than once $ cat testdata/names.csv \ | csvtk cut -f first_name,username,username first_name,username,username Rob,rob,rob Ken,ken,ken Robert,gri,gri Robert,abc,abc Robert,123,123 -
Unselect:
-
select 3+ columns:
csvtk cut -f -1,-2$ cat testdata/names.csv \ | csvtk cut -f -1,-2 last_name,username Pike,rob Thompson,ken Griesemer,gri Thompson,abc Abel,123 -
select columns except 1-3
$ cat testdata/names.csv \ | csvtk cut -f -1--3 username rob ken gri abc 123 -
select columns except
first_name:csvtk cut -f -first_name$ cat testdata/names.csv \ | csvtk cut -f -first_name id,last_name,username 11,Pike,rob 2,Thompson,ken 4,Griesemer,gri 1,Thompson,abc NA,Abel,123
-
-
Fuzzy fields using wildcard character,
csvtk cut -F -f "*_name,username"$ cat testdata/names.csv \ | csvtk cut -F -f "*_name,username" first_name,last_name,username Rob,Pike,rob Ken,Thompson,ken Robert,Griesemer,gri Robert,Thompson,abc Robert,Abel,123 -
All fields:
csvtk cut -F -f "*"orcsvtk cut -f 1-.$ cat testdata/names.csv \ | csvtk cut -F -f "*" id,first_name,last_name,username 11,Rob,Pike,rob 2,Ken,Thompson,ken 4,Robert,Griesemer,gri 1,Robert,Thompson,abc NA,Robert,Abel,123 -
Field ranges (read help message ("csvtk cut -f") for more examples)
-
csvtk cut -f 2-4for column 2,3,4$ cat testdata/names.csv \ | csvtk cut -f 2-4 first_name,last_name,username Rob,Pike,rob Ken,Thompson,ken Robert,Griesemer,gri Robert,Thompson,abc Robert,Abel,123 -
csvtk cut -f -3--1for discarding column 1,2,3# or -f -1--3 $ cat testdata/names.csv \ | csvtk cut -f -3--1 username rob ken gri abc 123 -
csvtk cut -f 2-,1for moving 1th column to the end.$ cat testdata/names.csv \ | csvtk cut -f 2-,1 first_name,last_name,username,id Rob,Pike,rob,11 Ken,Thompson,ken,2 Robert,Griesemer,gri,4 Robert,Thompson,abc,1 Robert,Abel,123,NA -
csvtk cut -f 1,1for duplicating columns$ cat testdata/names.csv \ | csvtk cut -f 1,1 id,id 11,11 2,2 4,4 1,1 NA,NA
-
del-header
Usage
delete column names
Attention:
1. It delete the first lines of all input files.
Usage:
csvtk del-header [flags]
Flags:
-h, --help help for del-header
Examples:
$ seq 3 | csvtk add-header
c1
1
2
3
$ seq 3 | csvtk add-header | csvtk del-header
1
2
3
$ seq 3 | csvtk del-header -H
1
2
3
del-quotes
Usage
remove extra double quotes added by 'fix-quotes'
Limitation:
1. Values containing line breaks are not supported.
Usage:
csvtk del-quotes [flags]
Flags:
-h, --help help for del-quotes
Examples: see eamples of fix-quotes
dim/nrow/ncol
Usage
dim:
dimensions of CSV file
Usage:
csvtk dim [flags]
Aliases:
dim, size, stats, stat
Flags:
--cols only print number of columns
-h, --help help for dim
-n, --no-files do not print file names
--rows only print number of rows
--tabular output in machine-friendly tabular format
nrow:
print number of records
Usage:
csvtk nrow [flags]
Aliases:
nrow, nrows
Flags:
-n, --file-name print file names
-h, --help help for nrow
ncol:
print number of columns
Usage:
csvtk ncol [flags]
Aliases:
ncol, ncols
Flags:
-n, --file-name print file names
-h, --help help for ncol
Examples
-
with header row
$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" $ cat testdata/names.csv | csvtk size file num_cols num_rows - 4 5 $ cat testdata/names.csv | csvtk nrow 5 $ cat testdata/names.csv | csvtk ncol 4 $ csvtk nrow testdata/names.csv testdata/phones.csv -n 5 testdata/names.csv 4 testdata/phones.csv -
no header row
$ cat testdata/digitals.tsv 4 5 6 1 2 3 7 8 0 8 1,000 4 $ cat testdata/digitals.tsv \ | csvtk size -t -H file num_cols num_rows - 3 4 $ cat testdata/names.csv | csvtk nrow -H 3 $ cat testdata/names.csv | csvtk ncol -H 4
filter
Usage
filter rows by values of selected fields with arithmetic expression
Usage:
csvtk filter [flags]
Flags:
--any print record if any of the field satisfy the condition
-f, --filter string filter condition. e.g. -f "age>12" or -f "1,3<=2" or -F -f "c*!=0"
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for filter
-n, --line-number print line number as the first column ("n")
Examples
-
single field
$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" $ cat testdata/names.csv \ | csvtk filter -f "id>0" \ | csvtk pretty id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc -
multiple fields
$ cat testdata/digitals.tsv 4 5 6 1 2 3 7 8 0 8 1,000 4 $ cat testdata/digitals.tsv \ | csvtk -t -H filter -f "1-3>0" 4 5 6 1 2 3 8 1,000 4using
--anyto print record if any of the field satisfy the condition$ cat testdata/digitals.tsv \ | csvtk -t -H filter -f "1-3>0" --any 4 5 6 1 2 3 7 8 0 8 1,000 4 -
fuzzy fields
$ cat testdata/names.csv \ | csvtk filter -F -f "i*!=0" id,first_name,last_name,username 11,Rob,Pike,rob 2,Ken,Thompson,ken 4,Robert,Griesemer,gri 1,Robert,Thompson,abc
filter2
Usage
filter rows by awk-like arithmetic/string expressions
The arithmetic/string expression is supported by:
https://github.com/Knetic/govaluate
Variables formats:
$1 or ${1} The first field/column
$a or ${a} Column "a"
${a,b} or ${a b} or ${a (b)} Column name with special charactors,
e.g., commas, spaces, and parentheses
Supported operators and types:
Modifiers: + - / * & | ^ ** % >> <<
Comparators: > >= < <= == != =~ !~ in
Logical ops: || &&
Numeric constants, as 64-bit floating point (12345.678)
String constants (single quotes: 'foobar')
Date constants (single quotes)
Boolean constants: true false
Parenthesis to control order of evaluation ( )
Arrays (anything separated by , within parenthesis: (1, 2, 'foo'))
Prefixes: ! - ~
Ternary conditional: ? :
Null coalescence: ??
Custom functions:
- len(), length of strings, e.g., len($1), len($a), len($1, $2)
- ulen(), length of unicode strings/width of unicode strings rendered
to a terminal, e.g., len("沈伟")==6, ulen("沈伟")==4
Usage:
csvtk filter2 [flags]
Flags:
-f, --filter string awk-like filter condition. e.g. '$age>12' or '$1 > $3' or '$name=="abc"' or
'$1 % 2 == 0'
-h, --help help for filter2
-n, --line-number print line number as the first column ("n")
-s, --numeric-as-string treat even numeric fields as strings to avoid converting big numbers into
scientific notation
Examples:
-
filter rows with
idgreater than 3:$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" $ cat testdata/names.csv \ | csvtk filter2 -f '$id > 3' id,first_name,last_name,username 11,Rob,Pike,rob 4,Robert,Griesemer,gri -
arithmetic and string expressions
$ cat testdata/names.csv \ | csvtk filter2 -f '$id > 3 || $username=="ken"' id,first_name,last_name,username 11,Rob,Pike,rob 2,Ken,Thompson,ken 4,Robert,Griesemer,gri -
More arithmetic expressions
$ cat testdata/digitals.tsv 4 5 6 1 2 3 7 8 0 8 1,000 4 $ cat testdata/digitals.tsv \ | csvtk filter2 -H -t -f '$1 > 2 && $2 % 2 == 0' 7 8 0 8 1,000 4 # comparison between fields and support $ cat testdata/digitals.tsv \ | csvtk filter2 -H -t -f '$2 <= $3 || ( $1 / $2 > 0.5 )' 4 5 6 1 2 3 7 8 0 -
Array expressions using
innumeric or string (case sensitive)$ cat testdata/names.csv | csvtk filter2 -f '$first_name in ("Ken", "Rob", "robert")' id,first_name,last_name,username\ 11,Rob,Pike,rob 2,Ken,Thompson,ken $ cat testdata/names.csv | csvtk filter2 -f '$id in (2, 4)' id,first_name,last_name,username 2,Ken,Thompson,ken 4,Robert,Griesemer,gri # negate by wrapping entire expression in `!()` $ cat testdata/names.csv | csvtk filter2 -f '!($username in ("rob", "ken"))' id,first_name,last_name,username 4,Robert,Griesemer,gri 1,Robert,Thompson,abc NA,Robert,Abel,123
fix
Usage
fix CSV/TSV with different numbers of columns in rows
How to:
1. First -n/--buf-rows rows are read to check the maximum number of columns.
The default value 0 means all rows will be read.
2. Buffered and remaining rows with fewer columns are appended with empty
cells before output.
3. An error will be reported if the number of columns of any remaining row
is larger than the maximum number of columns.
Usage:
csvtk fix [flags]
Flags:
-n, --buf-rows int the number of rows to determine the maximum number of columns. 0 for all rows.
-h, --help help for fix
Examples
$ cat testdata/unequal_ncols.csv
id,first_name,last_name
11,"Rob","Pike"
2,Ken,Thompson
4,"Robert","Griesemer","gri"
1,"Robert","Thompson","abc"
NA,"Robert"
$ cat testdata/unequal_ncols.csv | csvtk pretty
[ERRO] record on line 4: wrong number of fields
$ cat testdata/unequal_ncols.csv | csvtk fix | csvtk pretty -S grid
[INFO] the maximum number of columns in all 6 rows: 4
+----+------------+-----------+-----+
| id | first_name | last_name | |
+====+============+===========+=====+
| 11 | Rob | Pike | |
+----+------------+-----------+-----+
| 2 | Ken | Thompson | |
+----+------------+-----------+-----+
| 4 | Robert | Griesemer | gri |
+----+------------+-----------+-----+
| 1 | Robert | Thompson | abc |
+----+------------+-----------+-----+
| NA | Robert | | |
+----+------------+-----------+-----+
fix-quotes
Usage
fix malformed CSV/TSV caused by double-quotes
This command fixes fields not appropriately enclosed by double-quotes
to meet the RFC4180 standard (https://rfc-editor.org/rfc/rfc4180.html).
When and how to:
1. Values containing bare double quotes. e.g.,
a,abc" xyz,d
Error information: bare " in non-quoted-field.
Fix: adding the flag -l/--lazy-quotes.
Using this command:
a,abc" xyz,d -> a,"abc"" xyz",d
2. Values with double quotes in the begining but not in the end. e.g.,
a,"abc" xyz,d
Error information: extraneous or missing " in quoted-field.
Using this command:
a,"abc" xyz,d -> a,"""abc"" xyz",d
Next:
1. You can process the data without the flag -l/--lazy-quotes.
2. Use 'csvtk del-quotes' if you want to restore the original format.
Limitation:
1. Values containing line breaks are not supported.
Usage:
csvtk fix-quotes [flags]
Flags:
-b, --buffer-size string size of buffer, supported unit: K, M, G. You need increase the value when
"bufio.Scanner: token too long" error reported (default "1G")
-h, --help help for fix-quotes
Examples:
-
Test data, in which there are five cases with values containing double quotes.
$ cat testdata/malformed.tsv 1 Cellvibrio no quotes & not tab 2 "Cellvibrio gilvus" quotes can be removed 3 "quotes required" quotes needed (with a tab in the cell) 4 fake" record bare double-quote in non-quoted-field 5 "Cellvibrio" Winogradsky only with doub-quote in the beginning 6 fake record2" "only with doub-quote in the end" $ cat testdata/malformed.tsv | csvtk cut -f 1- [ERRO] parse error on line 2, column 3: bare " in non-quoted-field # -l does not work, and it's messed up. $ cat testdata/malformed.tsv | csvtk cut -f 1- -l 1 Cellvibrio no quotes & not tab "2 ""Cellvibrio gilvus"" quotes can be removed" "3 ""quotes required"" quotes needed (with a tab in the cell)" "4 fake"" record bare double-quote in non-quoted-field" "5 ""Cellvibrio"" Winogradsky only with doub-quote in the beginning" "6 fake record2"" ""only with doub-quote in the end""" -
Fix it!!!
$ cat testdata/malformed.tsv | csvtk fix-quotes -t 1 Cellvibrio no quotes & not tab 2 "Cellvibrio gilvus" quotes can be removed 3 "quotes required" quotes needed (with a tab in the cell) 4 "fake"" record" bare double-quote in non-quoted-field 5 """Cellvibrio"" Winogradsky" only with doub-quote in the beginning 6 "fake record2""" "only with doub-quote in the end" # pretty $ cat testdata/malformed.tsv | csvtk fix-quotes -t | csvtk pretty -Ht -S grid +---+--------------------------+----------------------------------------+ | 1 | Cellvibrio | no quotes & not tab | +---+--------------------------+----------------------------------------+ | 2 | Cellvibrio gilvus | quotes can be removed | +---+--------------------------+----------------------------------------+ | 3 | quotes required | quotes needed (with a tab in the cell) | +---+--------------------------+----------------------------------------+ | 4 | fake" record | bare double-quote in non-quoted-field | +---+--------------------------+----------------------------------------+ | 5 | "Cellvibrio" Winogradsky | only with doub-quote in the beginning | +---+--------------------------+----------------------------------------+ | 6 | fake record2" | only with doub-quote in the end | +---+--------------------------+----------------------------------------+ # do something, like searching rows containing double-quotes. # since the command-line argument parser csvtk uses parse the value of flag -p # as CSV data, we have to use -p '""""' to represents one double-quotes, # where the outter two double quotes are used to quote the value, # and the two inner double-quotes actually means an escaped double-quote # $ cat testdata/malformed.tsv \ | csvtk fix-quotes -t \ | csvtk grep -Ht -f 2 -r -p '""""' 4 "fake"" record" bare double-quote in non-quoted-field 5 """Cellvibrio"" Winogradsky" only with doub-quote in the beginning 6 "fake record2""" only with doub-quote in the end -
Note that fixed rows are different from the orginal ones, you can use
csvtk del-quotesto reset them.$ cat testdata/malformed.tsv \ | csvtk fix-quotes -t \ | csvtk filter2 -t -f '$1 > 0' \ | csvtk del-quotes -t 1 Cellvibrio no quotes & not tab 2 Cellvibrio gilvus quotes can be removed 3 "quotes required" quotes needed (with a tab in the cell) 4 fake" record bare double-quote in non-quoted-field 5 "Cellvibrio" Winogradsky only with doub-quote in the beginning 6 fake record2" only with doub-quote in the end
fmtdate
Usage
format date of selected fields
Date parsing is supported by: https://github.com/araddon/dateparse
Date formating is supported by: https://github.com/metakeule/fmtdate
Time zones:
format: Asia/Shanghai
whole list: https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
Output format is in MS Excel (TM) syntax.
Placeholders:
M - month (1)
MM - month (01)
MMM - month (Jan)
MMMM - month (January)
D - day (2)
DD - day (02)
DDD - day (Mon)
DDDD - day (Monday)
YY - year (06)
YYYY - year (2006)
hh - hours (15)
mm - minutes (04)
ss - seconds (05)
AM/PM hours: 'h' followed by optional 'mm' and 'ss' followed by 'pm', e.g.
hpm - hours (03PM)
h:mmpm - hours:minutes (03:04PM)
h:mm:sspm - hours:minutes:seconds (03:04:05PM)
Time zones: a time format followed by 'ZZZZ', 'ZZZ' or 'ZZ', e.g.
hh:mm:ss ZZZZ (16:05:06 +0100)
hh:mm:ss ZZZ (16:05:06 CET)
hh:mm:ss ZZ (16:05:06 +01:00)
Usage:
csvtk fmtdate [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
--format string output date format in MS Excel (TM) syntax, type "csvtk fmtdate -h" for
details (default "YYYY-MM-DD hh:mm:ss")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for fmtdate
-k, --keep-unparsed keep the key as value when no value found for the key
-z, --time-zone string timezone aka "Asia/Shanghai" or "America/Los_Angeles" formatted time-zone,
type "csvtk fmtdate -h" for details
Examples
$ csvtk xlsx2csv date.xlsx | csvtk pretty
data value
------------------- -----
2021-08-25 11:24:21 1
08/25/21 11:24 p8 2
NA 3
4
$ csvtk xlsx2csv date.xlsx \
| csvtk fmtdate --format "YYYY-MM-DD hh:mm:ss" \
| csvtk pretty
data value
------------------- -----
2021-08-25 11:24:21 1
2021-08-25 11:24:00 2
3
4
$ csvtk xlsx2csv date.xlsx \
| csvtk fmtdate --format "YYYY-MM-DD hh:mm:ss" -k \
| csvtk pretty
data value
------------------- -----
2021-08-25 11:24:21 1
2021-08-25 11:24:00 2
NA 3
4
fold
Usage
fold multiple values of a field into cells of groups
Attention:
Only grouping field and value fields are outputted.
Example:
$ echo -ne "id,value,meta\n1,a,12\n1,b,34\n2,c,56\n2,d,78\n" \
| csvtk pretty
id value meta
1 a 12
1 b 34
2 c 56
2 d 78
$ echo -ne "id,value,meta\n1,a,12\n1,b,34\n2,c,56\n2,d,78\n" \
| csvtk fold -f id -v value -s ";" \
| csvtk pretty
id value
1 a;b
2 c;d
$ echo -ne "id,value,meta\n1,a,12\n1,b,34\n2,c,56\n2,d,78\n" \
| csvtk fold -f id -v value -s ";" \
| csvtk unfold -f value -s ";" \
| csvtk pretty
id value
1 a
1 b
2 c
2 d
Usage:
csvtk fold [flags]
Aliases:
fold, collapse
Flags:
-f, --fields string key fields for grouping. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields (only for key fields), e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for fold
-i, --ignore-case ignore case
-s, --separater string separater for folded values (default "; ")
-v, --vfield string value field for folding
examples
-
data
$ csvtk pretty teachers.csv lab teacher class computational biology Tom Bioinformatics computational biology Tom Statistics computational biology Rob Bioinformatics sequencing center Jerry Bioinformatics sequencing center Nick Molecular Biology sequencing center Nick Microbiology -
List teachers for every lab/class.
uniqis used to deduplicate items.$ cat teachers.csv \ | csvtk uniq -f lab,teacher \ | csvtk fold -f lab -v teacher \ | csvtk pretty lab teacher computational biology Tom; Rob sequencing center Jerry; Nick $ cat teachers.csv \ | csvtk uniq -f class,teacher \ | csvtk fold -f class -v teacher -s ", " \ | csvtk pretty class teacher Statistics Tom Bioinformatics Tom, Rob, Jerry Molecular Biology Nick Microbiology Nick -
Multiple key fields supported
$ cat teachers.csv \ | csvtk fold -f teacher,lab -v class \ | csvtk pretty teacher lab class Tom computational biology Bioinformatics; Statistics Rob computational biology Bioinformatics Jerry sequencing center Bioinformatics Nick sequencing center Molecular Biology; Microbiology
freq
Usage
frequencies of selected fields
Usage:
csvtk freq [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-i, --ignore-case ignore case
-r, --reverse reverse order while sorting
-n, --sort-by-freq sort by frequency
-k, --sort-by-key sort by key
Examples
-
one filed
$ cat testdata/names.csv \ | csvtk freq -f first_name | csvtk pretty first_name frequency Ken 1 Rob 1 Robert 3 -
sort by frequency. you can also use
csvtk sortwith more sorting options$ cat testdata/names.csv \ | csvtk freq -f first_name -n -r \ | csvtk pretty first_name frequency Robert 3 Ken 1 Rob 1 -
sorty by key
$ cat testdata/names.csv \ | csvtk freq -f first_name -k \ | csvtk pretty first_name frequency Ken 1 Rob 1 Robert 3 -
multiple fields
$ cat testdata/names.csv \ | csvtk freq -f first_name,last_name \ | csvtk pretty first_name last_name frequency Robert Abel 1 Ken Thompson 1 Rob Pike 1 Robert Thompson 1 Robert Griesemer 1 -
data without header row
$ cat testdata/ testdata/digitals.tsv \ | csvtk -t -H freq -f 1 8 1 1 1 4 1 7 1
gather
Usage
gather columns into key-value pairs, like tidyr::gather/pivot_longer
Usage:
csvtk gather [flags]
Aliases:
gather, longer
Flags:
-f, --fields string fields for gathering. e.g -f 1,2 or -f columnA,columnB, or -f -columnA for
unselect columnA
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for longer
-k, --key string name of key column to create in output
-v, --value string name of value column to create in outpu
Examples:
$ cat testdata/names.csv | csvtk pretty -S simple
----------------------------------------
id first_name last_name username
----------------------------------------
11 Rob Pike rob
2 Ken Thompson ken
4 Robert Griesemer gri
1 Robert Thompson abc
NA Robert Abel 123
----------------------------------------
$ cat testdata/names.csv \
| csvtk gather -k item -v value -f -1 \
| csvtk pretty -S simple
-----------------------------
id item value
-----------------------------
11 first_name Rob
11 last_name Pike
11 username rob
2 first_name Ken
2 last_name Thompson
2 username ken
4 first_name Robert
4 last_name Griesemer
4 username gri
1 first_name Robert
1 last_name Thompson
1 username abc
NA first_name Robert
NA last_name Abel
NA username 123
-----------------------------
genautocomplete
Usage
generate shell autocompletion script
Supported shell: bash|zsh|fish|powershell
Bash:
# generate completion shell
csvtk genautocomplete --shell bash
# configure if never did.
# install bash-completion if the "complete" command is not found.
echo "for bcfile in ~/.bash_completion.d/* ; do source \$bcfile; done" >> ~/.bash_completion
echo "source ~/.bash_completion" >> ~/.bashrc
Zsh:
# generate completion shell
csvtk genautocomplete --shell zsh --file ~/.zfunc/_csvtk
# configure if never did
echo 'fpath=( ~/.zfunc "${fpath[@]}" )' >> ~/.zshrc
echo "autoload -U compinit; compinit" >> ~/.zshrc
fish:
csvtk genautocomplete --shell fish --file ~/.config/fish/completions/csvtk.fish
Usage:
csvtk genautocomplete [flags]
Flags:
--file string autocompletion file (default "/home/shenwei/.bash_completion.d/csvtk.sh")
-h, --help help for genautocomplete
--shell string autocompletion type (bash|zsh|fish|powershell) (default "bash")
grep
Usage
grep data by selected fields with patterns/regular expressions
Attentions:
1. By default, we directly compare the column value with patterns,
use "-r/--use-regexp" for partly matching.
2. Multiple patterns can be given by setting '-p/--pattern' more than once,
or giving comma separated values (CSV formats).
Therefore, please use double quotation marks for patterns containing
comma, e.g., -p '"A{2,}"'
Usage:
csvtk grep [flags]
Flags:
--delete-matched delete a pattern right after being matched, this keeps the firstly matched
data and speedups when using regular expressions
-f, --fields string comma separated key fields, column name or index. e.g. -f 1-3 or -f id,id2
or -F -f "group*" (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for grep
-i, --ignore-case ignore case
--immediate-output print output immediately, do not use write buffer
-v, --invert invert match
-n, --line-number print line number as the first column ("n")
-N, --no-highlight no highlight
-p, --pattern strings query pattern (multiple values supported). Attention: use double quotation
marks for patterns containing comma, e.g., -p '"A{2,}"'
-P, --pattern-file string pattern files (one pattern per line)
-r, --use-regexp patterns are regular expression
--verbose verbose output
Examples
Matched parts will be highlight.
-
By exact keys
$ cat testdata/names.csv \ | csvtk grep -f last_name -p Pike -p Abel \ | csvtk pretty id first_name last_name username 11 Rob Pike rob NA Robert Abel 123 # another form of multiple keys $ csvtk grep -f last_name -p Pike,Abel,Tom -
By regular expression:
csvtk grep -f first_name -r -p Rob$ cat testdata/names.csv \ | csvtk grep -f first_name -r -p Rob \ | csvtk pretty id first_name last_name username 11 Rob Pike rob 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 -
By pattern list
$ csvtk grep -f first_name -P name_list.txt -
Remore rows containing any missing data (NA):
$ csvtk grep -F -f "*" -r -p "^$" -v -
Show line number
$ cat names.csv \ | csvtk pretty id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 $ cat names.csv \ | csvtk grep -f first_name -r -i -p rob -n \ | csvtk pretty row id first_name last_name username --- -- ---------- --------- -------- 1 11 Rob Pike rob 3 4 Robert Griesemer gri 4 1 Robert Thompson abc 5 NA Robert Abel 123
head
Usage
print first N records
Tips:
- If you want to keep the first N records for each group, use
csvtk uniq -n 3
Usage:
csvtk head [flags]
Flags:
-n, --number int print first N records (default 10)
Examples
-
with header line
$ csvtk head -n 2 testdata/1.csv name,attr foo,cool bar,handsome -
no header line
$ csvtk head -H -n 2 testdata/1.csv name,attr foo,cool
headers
Usage
print headers
Usage:
csvtk headers [flags]
Flags:
-h, --help help for headers
-v, --verbose print verbose information
Examples
$ csvtk headers testdata/[12].csv
name
attr
name
major
$ csvtk headers testdata/[12].csv -v
# testdata/1.csv
1 name
2 attr
# testdata/2.csv
1 name
2 major
inter
Usage
intersection of multiple files
Attention:
1. fields in all files should be the same,
if not, extracting to another file using "csvtk cut".
Usage:
csvtk inter [flags]
Flags:
-f, --fields string select these fields as the key. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-i, --ignore-case ignore case
Examples:
$ cat testdata/phones.csv
username,phone
gri,11111
rob,12345
ken,22222
shenwei,999999
$ cat testdata/region.csv
name,region
ken,nowhere
gri,somewhere
shenwei,another
Thompson,there
$ csvtk inter testdata/phones.csv testdata/region.csv
username
gri
ken
shenwei
join
Usage
join files by selected fields (inner, left and outer join).
Attention:
1. Multiple keys supported
2. Default operation is inner join, use --left-join for left join
and --outer-join for outer join.
Usage:
csvtk join [flags]
Aliases:
join, merge
Flags:
-f, --fields string Semicolon separated key fields of all files, if given one, we think all the
files have the same key columns. Fields of different files should be separated
by ";", e.g -f "1;2" or -f "A,B;C,D" or -f id (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for join
-i, --ignore-case ignore case
-n, --ignore-null do not match NULL values
-k, --keep-unmatched keep unmatched data of the first file (left join)
-L, --left-join left join, equals to -k/--keep-unmatched, exclusive with --outer-join
--na string content for filling NA data
-P, --only-duplicates add filenames as colname prefixes or add custom suffixes only for duplicated
colnames
-O, --outer-join outer join, exclusive with --left-join
-p, --prefix-filename add each filename as a prefix to each colname. if there's no header row, we'll
add one
-e, --prefix-trim-ext trim extension when adding filename as colname prefix
-s, --suffix strings add suffixes to colnames from each file
Examples:
-
data
$ cat testdata/phones.csv username,phone gri,11111 rob,12345 ken,22222 shenwei,999999 $ cat testdata/region.csv name,region ken,nowhere gri,somewhere shenwei,another Thompson,there -
All files have same key column:
csvtk join -f id file1.csv file2.csv$ csvtk join -f 1 testdata/phones.csv testdata/region.csv \ | csvtk pretty username phone region gri 11111 somewhere ken 22222 nowhere shenwei 999999 another -
keep unmatched (left join)
$ csvtk join -f 1 testdata/phones.csv testdata/region.csv --left-join \ | csvtk pretty username phone region gri 11111 somewhere rob 12345 ken 22222 nowhere shenwei 999999 another -
keep unmatched and fill with something
$ csvtk join -f 1 testdata/phones.csv testdata/region.csv --left-join --na NA \ | csvtk pretty username phone region gri 11111 somewhere rob 12345 NA ken 22222 nowhere shenwei 999999 another -
Outer join
$ csvtk join -f 1 testdata/phones.csv testdata/region.csv --outer-join --na NA \ | csvtk pretty username phone region gri 11111 somewhere rob 12345 NA ken 22222 nowhere shenwei 999999 another Thompson NA there -
Files have different key columns:
csvtk join -f "username;username;name" testdata/names.csv phone.csv adress.csv -k. Note that fields are separated with;not,.$ csvtk join -f "username;name" testdata/phones.csv testdata/region.csv --left-join --na NA \ | csvtk pretty username phone region gri 11111 somewhere rob 12345 NA ken 22222 nowhere shenwei 999999 another -
Adding each filename as a prefix to each colname
$ cat testdata/1.csv name,attr foo,cool bar,handsome bob,beutiful $ cat testdata/2.csv name,major bar,bioinformatics bob,microbiology bob,computer science $ csvtk join testdata/{1,2}.csv \ | csvtk pretty name attr major ---- -------- ----------------- bar handsome bioinformatics bob beutiful microbiology bob beutiful computer science $ csvtk join testdata/{1,2}.csv --prefix-filename \ | csvtk pretty name 1.csv-attr 2.csv-major ---- ---------- ----------------- bar handsome bioinformatics bob beutiful microbiology bob beutiful computer science # trim the file extention $ csvtk join testdata/{1,2}.csv --prefix-filename --prefix-trim-ext \ | csvtk pretty name 1-attr 2-major ---- -------- ----------------- bar handsome bioinformatics bob beutiful microbiology bob beutiful computer science -
Adding each filename as a prefix to each colname for data without header row
$ cat testdata/A.f.csv a,x,1 b,y,2 $ cat testdata/B.f.csv a,x,3 b,y,4 $ cat testdata/C.f.csv a,x,5 b,y,6 $ csvtk join -H testdata/{A,B,C}.f.csv \ | csvtk pretty -H a x 1 x 3 x 5 b y 2 y 4 y 6 $ csvtk join -H testdata/{A,B,C}.f.csv -p \ | csvtk pretty key1 A.f.csv A.f.csv B.f.csv B.f.csv C.f.csv C.f.csv ---- ------- ------- ------- ------- ------- ------- a x 1 x 3 x 5 b y 2 y 4 y 6 # trim file extention $ csvtk join -H testdata/{A,B,C}.f.csv -p -e \ | csvtk pretty key1 A.f A.f B.f B.f C.f C.f ---- --- --- --- --- --- --- a x 1 x 3 x 5 b y 2 y 4 y 6 # use column 1 and 2 as keys $ csvtk join -H testdata/{A,B,C}.f.csv -p -e -f 1,2 \ | csvtk pretty key1 key2 A.f B.f C.f ---- ---- --- --- --- a x 1 3 5 b y 2 4 6 # change column names furthor $ csvtk join -H testdata/{A,B,C}.f.csv -p -e -f 1,2 \ | csvtk rename2 -F -f '*' -p '\.f$' \ | csvtk pretty key1 key2 A B C ---- ---- - - - a x 1 3 5 b y 2 4 6 -
add suffixes to colnames from each file (
-s/--suffix)$ csvtk join -H testdata/{A,B,C}.f.csv -s A,B,C \ | csvtk pretty key1 c2-A c3-A c2-B c3-B c2-C c3-C ---- ---- ---- ---- ---- ---- ---- a x 1 x 3 x 5 b y 2 y 4 y 6
mutate
Usage
create a new column from selected fields by regular expression
Usage:
csvtk mutate [flags]
Flags:
--after string insert the new column right after the given column name
--at int where the new column should appear, 1 for the 1st column, 0 for the last column
--before string insert the new column right before the given column name
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
-i, --ignore-case ignore case
--na for unmatched data, use blank instead of original data
-n, --name string new column name
-p, --pattern string search regular expression with capture bracket. e.g. (default "^(.+)$")
Examples
-
By default, copy a column:
csvtk mutate -f id -n newname -
Extract prefix of data as group name using regular expression (get "A" from "A.1" as group name):
csvtk mutate -f sample -n group -p "^(.+?)\." -
get the first letter as new column
$ cat testdata/phones.csv username,phone gri,11111 rob,12345 ken,22222 shenwei,999999 $ cat testdata/phones.csv \ | csvtk mutate -f username -p "^(\w)" -n first_letter username,phone,first_letter gri,11111,g rob,12345,r ken,22222,k shenwei,999999,s -
specify the position of the new column (see similar examples of
csvtk mutate2)$ cat testdata/phones.csv \ | csvtk mutate -f username -p "^(\w)" -n first_letter --at 2 username,first_letter,phone gri,g,11111 rob,r,12345 ken,k,22222 shenwei,s,999999 $ cat testdata/phones.csv \ | csvtk mutate -f username -p "^(\w)" -n first_letter --after username username,first_letter,phone gri,g,11111 rob,r,12345 ken,k,22222 shenwei,s,999999 $ cat testdata/phones.csv \ | csvtk mutate -f username -p "^(\w)" -n first_letter --before username first_letter,username,phone g,gri,11111 r,rob,12345 k,ken,22222 s,shenwei,99999
mutate2
Usage
create a new column from selected fields by awk-like arithmetic/string expressions
The arithmetic/string expression is supported by:
https://github.com/Knetic/govaluate
Variables formats:
$1 or ${1} The first field/column
$a or ${a} Column "a"
${a,b} or ${a b} or ${a (b)} Column name with special charactors,
e.g., commas, spaces, and parentheses
Supported operators and types:
Modifiers: + - / * & | ^ ** % >> <<
Comparators: > >= < <= == != =~ !~
Logical ops: || &&
Numeric constants, as 64-bit floating point (12345.678)
String constants (single quotes: 'foobar')
Date constants (single quotes)
Boolean constants: true false
Parenthesis to control order of evaluation ( )
Arrays (anything separated by , within parenthesis: (1, 2, 'foo'))
Prefixes: ! - ~
Ternary conditional: ? :
Null coalescence: ??
Custom functions:
- len(), length of strings, e.g., len($1), len($a), len($1, $2)
- ulen(), length of unicode strings/width of unicode strings rendered
to a terminal, e.g., len("沈伟")==6, ulen("沈伟")==4
Usage:
csvtk mutate2 [flags]
Flags:
--after string insert the new column right after the given column name
--at int where the new column should appear, 1 for the 1st column, 0 for the last column
--before string insert the new column right before the given column name
-w, --decimal-width int limit floats to N decimal points (default 2)
-e, --expression string arithmetic/string expressions. e.g. "'string'", '"abc"', ' $a + "-" + $b ',
'$1 + $2', '$a / $b', ' $1 > 100 ? "big" : "small" '
-h, --help help for mutate2
-n, --name string new column name
-s, --numeric-as-string treat even numeric fields as strings to avoid converting big numbers into
scientific notation
Example
-
Constants
$ cat testdata/digitals.tsv \ | csvtk mutate2 -t -H -e " 'abc' " 4 5 6 abc 1 2 3 abc 7 8 0 abc 8 1,000 4 abc $ val=123 \ && cat testdata/digitals.tsv \ | csvtk mutate2 -t -H -e " $val " 4 5 6 123 1 2 3 123 7 8 0 123 8 1,000 4 123 -
String concatenation
$ cat testdata/names.csv \ | csvtk mutate2 -n full_name -e ' $first_name + " " + $last_name ' \ | csvtk pretty id first_name last_name username full_name 11 Rob Pike rob Rob Pike 2 Ken Thompson ken Ken Thompson 4 Robert Griesemer gri Robert Griesemer 1 Robert Thompson abc Robert Thompson NA Robert Abel 123 Robert Abel -
Math
$ cat testdata/digitals.tsv | csvtk mutate2 -t -H -e '$1 + $3' -w 0 4 5 6 10 1 2 3 4 7 8 0 7 8 1,000 4 12 -
Bool
$ cat testdata/digitals.tsv | csvtk mutate2 -t -H -e '$1 > 5' 4 5 6 false 1 2 3 false 7 8 0 true 8 1,000 4 true -
Ternary condition (
? :)$ cat testdata/digitals.tsv | csvtk mutate2 -t -H -e '$1 > 5 ? "big" : "small" ' 4 5 6 small 1 2 3 small 7 8 0 big 8 1,000 4 big -
Null coalescence (
??)$ echo -e "one,two\na1,a2\n,b2\na2," | csvtk pretty one two --- --- a1 a2 b2 a2 $ echo -e "one,two\na1,a2\n,b2\na2," \ | csvtk mutate2 -n three -e '$one ?? $two' \ | csvtk pretty one two three --- --- ----- a1 a2 a1 b2 b2 a2 a2 -
Specify the position of the new column
$ echo -ne "a,b,c\n1,2,3\n" a,b,c 1,2,3 # in the end (default) $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate2 -e '$a+$c' -n x -w 0 a,b,c,x 1,2,3,4 # in the beginning $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate2 -e '$a+$c' -n x -w 0 --at 1 x,a,b,c 4,1,2,3 # at another position $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate2 -e '$a+$c' -n x -w 0 --at 3 a,b,x,c 1,2,4,3 # right after the given column name $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate2 -e '$a+$c' -n x -w 0 --after a a,x,b,c 1,4,2,3 # right before the given column name $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate2 -e '$a+$c' -n x -w 0 --before c a,b,x,c 1,2,4,3
mutate3
Usage
create a new column from selected fields with Go-like expressions
The expression language is supported by Expr:
https://expr-lang.org/docs/language-definition
Variables formats:
$1 or ${1} The first field/column
$a or ${a} Column "a"
${a,b} or ${a b} or ${a (b)} Column name with special charactors,
e.g., commas, spaces, and parentheses
Supported Operators:
Arithmetic: + - / * ^ ** %
Comparison: > >= < <= == !=
Logical: not ! and && or ||
String: + contains startsWith endsWith
Regex: matches
Range: ..
Slice: [:]
Pipe: |
Ternary conditional: ? :
Null coalescence: ??
Supported Literals:
Arrays: [1, 2, 3]
Boolean: true false
Float: 0.5 .5
Integer: 42 0x2A 0o52 0b101010
Map: {a: 1, b: 2}
Null: nil
String: "foo" 'bar'
See Expr language definition link for documentation on built-in functions.
Custom functions:
- ulen(), length of unicode strings/width of unicode strings rendered
to a terminal, e.g., len("沈伟")==6, ulen("沈伟")==4
Usage:
csvtk mutate3 [flags]
Flags:
--after string insert the new column right after the given column name
--at int where the new column should appear, 1 for the 1st column, 0 for the last column
--before string insert the new column right before the given column name
-w, --decimal-width int limit floats to N decimal points (default 2)
-e, --expression string arithmetic/string expressions. e.g. "'string'", '"abc"', ' $a + "-" + $b ',
'$1 + $2', '$a / $b', ' $1 > 100 ? "big" : "small" '
-h, --help help for mutate3
-n, --name string new column name
-s, --numeric-as-string treat even numeric fields as strings to avoid converting big numbers into
scientific notation
Examples
-
Constants
$ cat testdata/digitals.tsv \ | csvtk mutate3 -t -H -e " 'abc' " 4 5 6 abc 1 2 3 abc 7 8 0 abc 8 1,000 4 abc $ val=123 \ && cat testdata/digitals.tsv \ | csvtk mutate3 -t -H -e " $val " 4 5 6 123 1 2 3 123 7 8 0 123 8 1,000 4 123 -
String concatenation
$ cat testdata/names.csv \ | csvtk mutate3 -n full_name -e ' $first_name + " " + $last_name ' \ | csvtk pretty id first_name last_name username full_name 11 Rob Pike rob Rob Pike 2 Ken Thompson ken Ken Thompson 4 Robert Griesemer gri Robert Griesemer 1 Robert Thompson abc Robert Thompson NA Robert Abel 123 Robert Abel -
Math
$ cat testdata/digitals.tsv | csvtk mutate3 -t -H -e '$1 + $3' -w 0 4 5 6 10 1 2 3 4 7 8 0 7 8 1,000 4 12 -
Bool
$ cat testdata/digitals.tsv | csvtk mutate3 -t -H -e '$1 > 5' 4 5 6 false 1 2 3 false 7 8 0 true 8 1,000 4 true -
Ternary condition (
? :)$ cat testdata/digitals.tsv | csvtk mutate3 -t -H -e '$1 > 5 ? "big" : "small" ' 4 5 6 small 1 2 3 small 7 8 0 big 8 1,000 4 big -
Null coalescence (
??)$ echo -e "one,two\na1,a2\n,b2\na2," | csvtk pretty one two --- --- a1 a2 b2 a2 $ echo -e "one,two\na1,a2\n,b2\na2," \ | csvtk mutate3 -n three -e '$one ?? $two' \ | csvtk pretty one two three --- --- ----- a1 a2 a1 b2 b2 a2 a2 -
Specify the position of the new column
$ echo -ne "a,b,c\n1,2,3\n" a,b,c 1,2,3 # in the end (default) $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate3 -e '$a+$c' -n x -w 0 a,b,c,x 1,2,3,4 # in the beginning $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate3 -e '$a+$c' -n x -w 0 --at 1 x,a,b,c 4,1,2,3 # at another position $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate3 -e '$a+$c' -n x -w 0 --at 3 a,b,x,c 1,2,4,3 # right after the given column name $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate3 -e '$a+$c' -n x -w 0 --after a a,x,b,c 1,4,2,3 # right before the given column name $ echo -ne "a,b,c\n1,2,3\n" | csvtk mutate3 -e '$a+$c' -n x -w 0 --before c a,b,x,c 1,2,4,3
plot
Usage
plot common figures
Notes:
1. Output file can be set by flag -o/--out-file.
2. File format is determined by the out file suffix.
Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
3. If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to "display" command of Imagemagic
or just redirect to file.
Usage:
csvtk plot [command]
Available Commands:
bar plot bar chart
box plot boxplot
hist plot histogram
line line plot and scatter plot
Flags:
--axis-width float axis width (default 1.5)
-f, --data-field string column index or column name of data (default "1")
--format string image format for stdout when flag -o/--out-file not given. available
values: eps, jpg|jpeg, pdf, png, svg, and tif|tiff. (default "png")
-g, --group-field string column index or column name of group
--height float Figure height (default 4.5)
-h, --help help for plot
--hide-x-labs hide X axis, ticks, and tick labels
--hide-y-labs hide Y axis, ticks, and tick labels
--label-size int label font size (default 14)
--na-values strings NA values, case ignored (default [,NA,N/A])
--scale float scale the image width/height, tick, axes, line/point and font sizes
proportionally (default 1)
--skip-na skip NA values in --na-values
--tick-label-size float tick label font size (default 12)
--tick-width float axis tick width (default 1.5)
--title string Figure title
--title-size int title font size (default 16)
--width float Figure width (default 6)
--x-max string maximum value of X axis
--x-min string minimum value of X axis
--x-scale-ln scale the X axis by the natural log
--xlab string x label text
--y-max string maximum value of Y axis
--y-min string minimum value of Y axis
--y-scale-ln scale the Y axis by the natural log
--ylab string y label text
Global Flags:
-C, --comment-char string lines starting with commment-character will be ignored. if your header
row starts with '#', please assign "-C" another rare symbol, e.g. '$'
(default "#")
-U, --delete-header do not output header row
-d, --delimiter string delimiting character of the input CSV file (default ",")
-E, --ignore-empty-row ignore empty rows
-I, --ignore-illegal-row ignore illegal rows. You can also use 'csvtk fix' to fix files with
different numbers of columns in rows
-X, --infile-list string file of input files list (one file per line), if given, they are appended
to files from cli arguments
-l, --lazy-quotes if given, a quote may appear in an unquoted field and a non-doubled quote
may appear in a quoted field
-H, --no-header-row specifies that the input CSV file does not have header row
-j, --num-cpus int number of CPUs to use (default 4)
-D, --out-delimiter string delimiting character of the output CSV file, e.g., -D $'\t' for tab
(default ",")
-o, --out-file string out file ("-" for stdout, suffix .gz for gzipped out) (default "-")
-T, --out-tabs specifies that the output is delimited with tabs. Overrides "-D"
--quiet be quiet and do not show extra information and warnings
-Z, --show-row-number show row number as the first column, with header row skipped
-t, --tabs specifies that the input CSV file is delimited with tabs. Overrides "-d"
-V, --version print version information
Note that most of the flags of plot are global flags of the subcommands
hist, box and line
Notes of image output
- Output file can be set by flag -o/--out-file.
- File format is determined by the out file suffix. Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
- If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to
displaycommand ofImagemagicor just redirect to file.
plot box
Usage
plot boxplot
Notes:
1. Output file can be set by flag -o/--out-file.
2. File format is determined by the out file suffix.
Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
3. If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to "display" command of Imagemagic
or just redirect to file.
Usage:
csvtk plot box [flags]
Flags:
--box-width float box width
--color-index int color index, 1-7 (default 1)
-h, --help help for box
--horiz horize box plot
--line-width float line width (default 1.5)
--point-size float point size (default 3)
Examples
-
plot boxplot with data of the "GC Content" (third) column, group information is the "Group" column.
csvtk -t plot box testdata/grouped_data.tsv.gz -g "Group" -f "GC Content" \ --width 3 --title "Box plot" \ > boxplot.png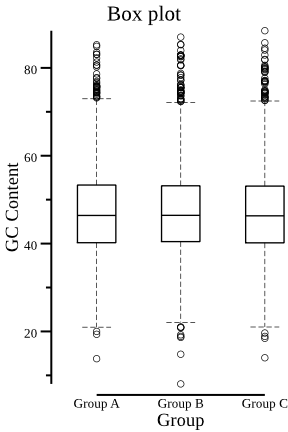
-
plot horiz boxplot with data of the "Length" (second) column, group information is the "Group" column.
$ csvtk -t plot box testdata/grouped_data.tsv.gz -g "Group" -f "Length" \ --height 3 --width 5 --horiz --title "Horiz box plot" \ > boxplot2.png`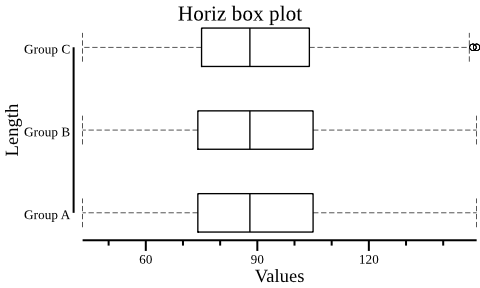
plot hist
Usage
plot histogram
Notes:
1. Output file can be set by flag -o/--out-file.
2. File format is determined by the out file suffix.
Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
3. If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to "display" command of Imagemagic
or just redirect to file.
Usage:
csvtk plot hist [flags]
Flags:
--bins int number of bins (default 50)
--color-index int color index, 1-7 (default 1)
-h, --help help for hist
--line-width float line width (default 1)
--percentiles calculate percentiles
Examples
-
example data
$ zcat testdata/grouped_data.tsv.gz | head -n 5 | csvtk -t pretty Group Length GC Content Group A 97 57.73 Group A 95 49.47 Group A 97 49.48 Group A 100 51.00 -
plot histogram with data of the second column:
$ csvtk -t plot hist testdata/grouped_data.tsv.gz -f 2 \ --title Histogram -o histogram.png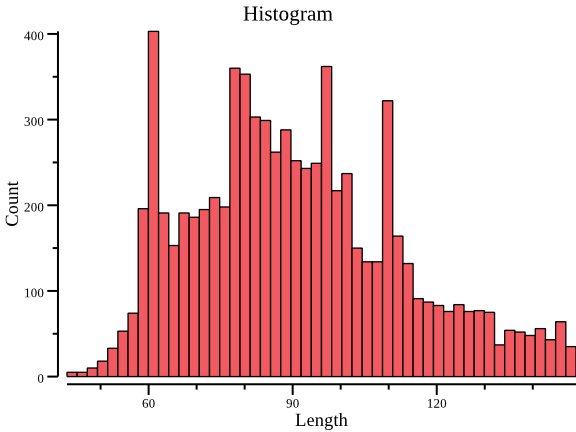
-
You can also write image to stdout and pipe to "display" command of Imagemagic:
$ csvtk -t plot hist testdata/grouped_data.tsv.gz -f 2 | display
plot line
Usage
line plot and scatter plot
Notes:
1. Output file can be set by flag -o/--out-file.
2. File format is determined by the out file suffix.
Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
3. If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to "display" command of Imagemagic
or just redirect to file.
Usage:
csvtk plot line [flags]
Flags:
--color-index int color index, 1-7 (default 1)
-x, --data-field-x string column index or column name of X for command line
--data-field-x-nominal data field X is treated as a nominal field
-y, --data-field-y string column index or column name of Y for command line
-h, --help help for line
--legend-left locate legend along the left edge of the plot
--legend-top locate legend along the top edge of the plot
--line-width float line width (default 1.5)
--point-size float point size (default 3)
--scatter only plot points
Examples
-
example data
$ head -n 5 testdata/xy.tsv Group X Y A 0 1 A 1 1.3 A 1.5 1.5 A 2.0 2 -
plot line plot with X-Y data
$ csvtk -t plot line testdata/xy.tsv -x X -y Y -g Group \ --title "Line plot" \ > lineplot.png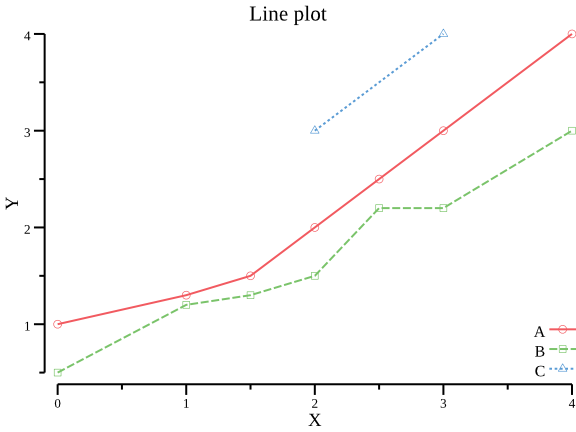
-
plot scatter
$ csvtk -t plot line testdata/xy.tsv -x X -y Y -g Group \ --title "Scatter" --scatter \ > lineplot.png
-
sortable nominal values. see also #308
$ csvtk pretty testdata/date2value.csv date views unique_visitors ----- ----- --------------- 03/01 7 5 03/02 5 3 03/03 39 21 03/04 37 20 03/05 59 25 03/06 23 14 03/07 49 24 $ cat testdata/date2value.csv \ | csvtk gather -f 2- -k type -v count \ | csvtk plot line --group-field type -x date -y count --data-field-x-nominal \ > testdata/figures/line_plot_date.png
plot bar
Usage
plot bar chart
Notes:
1. Output file can be set by flag -o/--out-file.
2. File format is determined by the out file suffix.
Supported formats: eps, jpg|jpeg, pdf, png, svg, and tif|tiff
3. If flag -o/--out-file not set (default), image is written to stdout,
you can display the image by pipping to "display" command of Imagemagic
or just redirect to file.
Usage:
csvtk plot bar [flags]
Flags:
--bar-width float bar width (0 for auto)
--color-index int color index, 1-7 (default 1)
-x, --data-field-x string column index or column name of X for command bar
-y, --data-field-y string column index or column name of Y for command bar
-h, --help help for bar
--horizontal horizontal bar chart
--legend-left locate legend along the left edge of the plot
--legend-top locate legend along the top edge of the plot
pretty
Usage
convert CSV to a readable aligned table
How to:
1. First -n/--buf-rows rows are read to check the minimum and maximum widths
of each columns.
You can also set the global or column-specific (the number of values need
equal to the number of columns) thresholds via -w/--min-width and -W/--max-width.
1a. Cells longer than the maximum width will be wrapped (default) or
clipped (--clip).
Usually, the text is wrapped in space (-x/--wrap-delimiter). But if one
word is longer than the -W/--max-width, it will be force split.
1b. Texts are aligned left (default), center (-m/--align-center)
or right (-r/--align-right). Users can specify columns with column names,
field indexes or ranges.
Examples:
-m A,B # column A and B
-m 1,2 # 1st and 2nd column
-m -1 # the last column (it's not unselecting in other commands)
-m 1,3-5 # 1st, from 3rd to 5th column
-m 1- # 1st and later columns (all columns)
-m -3- # the last 3 columns
-m -3--2 # the 2nd and 3rd to last columns
-m 1- -r -1 # all columns are center-aligned, except the last column
# which is right-aligned. -r overides -m.
2. Remaining rows are read and immediately outputted, one by one, till the end.
Styles:
Some preset styles are provided (-S/--style).
default:
id size
-- ----
1 Huge
2 Tiny
plain:
id size
1 Huge
2 Tiny
simple:
-----------
id size
-----------
1 Huge
2 Tiny
-----------
3line:
━━━━━━━━━━━
id size
───────────
1 Huge
2 Tiny
━━━━━━━━━━━
grid:
+----+------+
| id | size |
+====+======+
| 1 | Huge |
+----+------+
| 2 | Tiny |
+----+------+
light:
┌----┬------┐
| id | size |
├====┼======┤
| 1 | Huge |
├----┼------┤
| 2 | Tiny |
└----┴------┘
regular:
┌────┬──────┐
│ id │ size │
├────┼──────┤
│ 1 │ Huge │
├────┼──────┤
│ 2 │ Tiny │
└────┴──────┘
round:
╭────┬──────╮
│ id │ size │
├────┼──────┤
│ 1 │ Huge │
├────┼──────┤
│ 2 │ Tiny │
╰────┴──────╯
bold:
┏━━━━┳━━━━━━┓
┃ id ┃ size ┃
┣━━━━╋━━━━━━┫
┃ 1 ┃ Huge ┃
┣━━━━╋━━━━━━┫
┃ 2 ┃ Tiny ┃
┗━━━━┻━━━━━━┛
double:
╔════╦══════╗
║ id ║ size ║
╠════╬══════╣
║ 1 ║ Huge ║
╠════╬══════╣
║ 2 ║ Tiny ║
╚════╩══════╝
Usage:
csvtk pretty [flags]
Flags:
-m, --align-center strings align right for selected columns (field index/range or column name, type
"csvtk pretty -h" for examples)
-r, --align-right strings align right for selected columns (field index/range or column name, type
"csvtk pretty -h" for examples)
-n, --buf-rows int the number of rows to determine the min and max widths (0 for all rows)
(default 1024)
--clip clip longer cell instead of wrapping
--clip-mark string clip mark (default "...")
-h, --help help for pretty
-W, --max-width strings max width, multiple values (max widths for each column, 0 for no limit)
should be separated by commas. E.g., -W 40,20,0 limits the max widths of
1st and 2nd columns
-w, --min-width strings min width, multiple values (min widths for each column, 0 for no limit)
should be separated by commas. E.g., -w 0,10,10 limits the min widths of
2nd and 3rd columns
-s, --separator string fields/columns separator (default " ")
-S, --style string output syle. available vaules: default, plain, simple, 3line, grid,
light, round, bold, double. check https://github.com/shenwei356/stable
-x, --wrap-delimiter string delimiter for wrapping cells (default " ")
Examples:
-
default
$ csvtk pretty testdata/names.csv id first_name last_name username -- ---------- --------- -------- 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 $ csvtk pretty testdata/names.csv -H id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 -
tree-line table
$ cat testdata/names.csv | csvtk pretty -S 3line ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ id first_name last_name username ──────────────────────────────────────── 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ $ cat testdata/names.csv | csvtk pretty -S 3line -H ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ -
align right/center for some columns
$ csvtk pretty testdata/names.csv -w 6 -S regular -r 1,username -m first_name ┌────────┬────────────┬───────────┬──────────┐ │ id │ first_name │ last_name │ username │ ├────────┼────────────┼───────────┼──────────┤ │ 11 │ Rob │ Pike │ rob │ ├────────┼────────────┼───────────┼──────────┤ │ 2 │ Ken │ Thompson │ ken │ ├────────┼────────────┼───────────┼──────────┤ │ 4 │ Robert │ Griesemer │ gri │ ├────────┼────────────┼───────────┼──────────┤ │ 1 │ Robert │ Thompson │ abc │ ├────────┼────────────┼───────────┼──────────┤ │ NA │ Robert │ Abel │ 123 │ └────────┴────────────┴───────────┴──────────┘ $ csvtk pretty testdata/names.csv -w 6 -S bold -m 1- -r -1 ┏━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┓ ┃ id ┃ first_name ┃ last_name ┃ username ┃ ┣━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━╋━━━━━━━━━━┫ ┃ 11 ┃ Rob ┃ Pike ┃ rob ┃ ┣━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━╋━━━━━━━━━━┫ ┃ 2 ┃ Ken ┃ Thompson ┃ ken ┃ ┣━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━╋━━━━━━━━━━┫ ┃ 4 ┃ Robert ┃ Griesemer ┃ gri ┃ ┣━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━╋━━━━━━━━━━┫ ┃ 1 ┃ Robert ┃ Thompson ┃ abc ┃ ┣━━━━━━━━╋━━━━━━━━━━━━╋━━━━━━━━━━━╋━━━━━━━━━━┫ ┃ NA ┃ Robert ┃ Abel ┃ 123 ┃ ┗━━━━━━━━┻━━━━━━━━━━━━┻━━━━━━━━━━━┻━━━━━━━━━━┛ -
custom separator
$ csvtk pretty testdata/names.csv -s " | " id | first_name | last_name | username -- | ---------- | --------- | -------- 11 | Rob | Pike | rob 2 | Ken | Thompson | ken 4 | Robert | Griesemer | gri 1 | Robert | Thompson | abc NA | Robert | Abel | 123 -
Set the global minimum and maximum width.
$ csvtk pretty testdata/long.csv -w 5 -W 40 id name message ----- ------------------ ---------------------------------------- 1 Donec Vitae Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse. 2 Quaerat Voluptatem At vero eos et accusamus et iusto odio. 3 Aliquam lorem Curabitur ullamcorper ultricies nisi. Nam eget dui. Etiam rhoncus. Maecenas tempus, tellus eget condimentum rhoncus, sem quam semper libero. -
Set min and max widths for all columns.
$ csvtk pretty testdata/long.csv -w 5,25,0 -W 0,30,40 -m 1,2 -S round ╭-------┬---------------------------┬------------------------------------------╮ | id | name | message | ├=======┼===========================┼==========================================┤ | 1 | Donec Vitae | Quis autem vel eum iure reprehenderit | | | | qui in ea voluptate velit esse. | ├-------┼---------------------------┼------------------------------------------┤ | 2 | Quaerat Voluptatem | At vero eos et accusamus et iusto odio. | ├-------┼---------------------------┼------------------------------------------┤ | 3 | Aliquam lorem | Curabitur ullamcorper ultricies nisi. | | | | Nam eget dui. Etiam rhoncus. Maecenas | | | | tempus, tellus eget condimentum | | | | rhoncus, sem quam semper libero. | ╰-------┴---------------------------┴------------------------------------------╯ -
Clipping cells instead of wrapping
$ csvtk pretty testdata/long.csv -w 5 -W 40 --clip id name message ----- ------------------ ---------------------------------------- 1 Donec Vitae Quis autem vel eum iure reprehenderit... 2 Quaerat Voluptatem At vero eos et accusamus et iusto odio. 3 Aliquam lorem Curabitur ullamcorper ultricies nisi.... -
Change the output style
$ csvtk pretty testdata/long.csv -W 40 -S round ╭────┬────────────────────┬──────────────────────────────────────────╮ │ id │ name │ message │ ├────┼────────────────────┼──────────────────────────────────────────┤ │ 1 │ Donec Vitae │ Quis autem vel eum iure reprehenderit │ │ │ │ qui in ea voluptate velit esse. │ ├────┼────────────────────┼──────────────────────────────────────────┤ │ 2 │ Quaerat Voluptatem │ At vero eos et accusamus et iusto odio. │ ├────┼────────────────────┼──────────────────────────────────────────┤ │ 3 │ Aliquam lorem │ Curabitur ullamcorper ultricies nisi. │ │ │ │ Nam eget dui. Etiam rhoncus. Maecenas │ │ │ │ tempus, tellus eget condimentum │ │ │ │ rhoncus, sem quam semper libero. │ ╰────┴────────────────────┴──────────────────────────────────────────╯ -
Custom delimiter for wrapping
$ csvtk pretty testdata/lineages.csv -W 60 -x ';' -S light ┌-------┬------------------┬--------------------------------------------------------------┐ | taxid | name | complete lineage | ├=======┼==================┼==============================================================┤ | 9606 | Homo sapiens | cellular organisms;Eukaryota;Opisthokonta;Metazoa;Eumetazoa; | | | | Bilateria;Deuterostomia;Chordata;Craniata;Vertebrata; | | | | Gnathostomata;Teleostomi;Euteleostomi;Sarcopterygii; | | | | Dipnotetrapodomorpha;Tetrapoda;Amniota;Mammalia;Theria; | | | | Eutheria;Boreoeutheria;Euarchontoglires;Primates; | | | | Haplorrhini;Simiiformes;Catarrhini;Hominoidea;Hominidae; | | | | Homininae;Homo;Homo sapiens | ├-------┼------------------┼--------------------------------------------------------------┤ | 562 | Escherichia coli | cellular organisms;Bacteria;Pseudomonadota; | | | | Gammaproteobacteria;Enterobacterales;Enterobacteriaceae; | | | | Escherichia;Escherichia coli | └-------┴------------------┴--------------------------------------------------------------┘
rename
Usage
rename column names with new names
Usage:
csvtk rename [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-n, --names string comma separated new names
Examples:
-
Setting new names:
csvtk rename -f A,B -n a,borcsvtk rename -f 1-3 -n a,b,c$ cat testdata/phones.csv username,phone gri,11111 rob,12345 ken,22222 shenwei,999999 $ cat testdata/phones.csv \ | csvtk rename -f 1-2 -n 姓名,电话 \ | csvtk pretty 姓名 电话 gri 11111 rob 12345 ken 22222 shenwei 999999 -
Also support any order
$ cat testdata/phones.csv \ | csvtk rename -f 2,1 -n 电话,姓名 \ | csvtk pretty 姓名 电话 gri 11111 rob 12345 ken 22222 shenwei 999999
rename2
Usage
rename column names by regular expression
Special replacement symbols:
{nr} ascending number, starting from --start-num
{kv} Corresponding value of the key (captured variable $n) by key-value file,
n can be specified by flag --key-capt-idx (default: 1)
Usage:
csvtk rename2 [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for rename2
-i, --ignore-case ignore case
-K, --keep-key keep the key as value when no value found for the key
--key-capt-idx int capture variable index of key (1-based) (default 1)
--key-miss-repl string replacement for key with no corresponding value
-k, --kv-file string tab-delimited key-value file for replacing key with value
when using "{kv}" in -r (--replacement)
-A, --kv-file-all-left-columns-as-value treat all columns except 1th one as value for kv-file with
more than 2 columns
--nr-width int minimum width for {nr} in flag -r/--replacement. e.g.,
formating "1" to "001" by --nr-width 3 (default 1)
-p, --pattern string search regular expression
-r, --replacement string renamement. supporting capture variables. e.g. $1
represents the text of the first submatch. ATTENTION: use
SINGLE quote NOT double quotes in *nix OS or use the \
escape character. Ascending number is also supported by
"{nr}".use ${1} instead of $1 when {kv} given!
-n, --start-num int starting number when using {nr} in replacement (default 1)
Examples:
-
Add suffix to all column names.
$ cat testdata/phones.csv username,phone gri,11111 rob,12345 ken,22222 shenwei,999999 $ cat testdata/phones.csv \ | csvtk rename2 -F -f "*" -p "(.*)" -r 'prefix_${1}_suffix' prefix_username_suffix,prefix_phone_suffix gri,11111 rob,12345 ken,22222 shenwei,999999 -
supporting
{kv}and{nr}incsvtk replace. e.g., replace barcode with sample name.$ cat barcodes.tsv Sample Barcode sc1 CCTAGATTAAT sc2 GAAGACTTGGT sc3 GAAGCAGTATG sc4 GGTAACCTGAC sc5 ATAGTTCTCGT $ cat table.tsv gene ATAGTTCTCGT GAAGCAGTATG GAAGACTTGGT AAAAAAAAAA gene1 0 0 3 0 gen1e2 0 0 0 0 # note that, we must arrange the order of barcodes.tsv to KEY-VALUE $ csvtk cut -t -f 2,1 barcodes.tsv Barcode Sample CCTAGATTAAT sc1 GAAGACTTGGT sc2 GAAGCAGTATG sc3 GGTAACCTGAC sc4 ATAGTTCTCGT sc5 # here we go!!!! $ csvtk rename2 -t -k <(csvtk cut -t -f 2,1 barcodes.tsv) \ -f -1 -p '(.+)' -r '{kv}' --key-miss-repl unknown table.tsv gene sc5 sc3 sc2 unknown gene1 0 0 3 0 gen1e2 0 0 0 0 -
{nr}, incase you need this$ echo "a,b,c,d" \ | csvtk rename2 -p '(.+)' -r 'col_{nr}' -f -1 --start-num 2 a,col_2,col_3,col_4
replace
Usage
replace data of selected fields by regular expression
Note that the replacement supports capture variables.
e.g. $1 represents the text of the first submatch.
ATTENTION: use SINGLE quote NOT double quotes in *nix OS.
Examples: Adding space to cell values.
csvtk replace -p "(.)" -r '$1 '
Or use the \ escape character.
csvtk replace -p "(.)" -r "\$1 "
more on: http://shenwei356.github.io/csvtk/usage/#replace
Special replacement symbols:
{nr} Record number, starting from 1
{gnr} Record number within a group, defined by value(s) of field(s) via -g/--group
{enr} Enumeration numbering of groups, defined by value(s) of field(s) via -g/--group
{rnr} Running numbering of groups, defined by value(s) of field(s) via -g/--group
Examples:
group {nr} {gnr} {enr} {rnr}
A 1 1 1 1
A 2 2 1 1
B 3 1 2 2
B 4 2 2 2
A 5 3 1 3
C 6 1 3 4
{kv} Corresponding value of the key (captured variable $n) by key-value file,
n can be specified by flag --key-capt-idx (default: 1)
Usage:
csvtk replace [flags]
Flags:
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB
(default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-g, --group strings select field(s) for group-specific record numbering,
including {gnr}, {enr}, {rnr}. Please use the same field
type (field number or column name) with the value of -f/--fields
-h, --help help for replace
-i, --ignore-case ignore case
--incr-num int increment number when using {nr}, {gnr}, {enr}, {rnr} in
replacement (default 1)
-K, --keep-key keep the key as value when no value found for the key
--key-capt-idx int capture variable index of key (1-based) (default 1)
--key-miss-repl string replacement for key with no corresponding value
-k, --kv-file string tab-delimited key-value file for replacing key with value
when using "{kv}" in -r (--replacement)
-A, --kv-file-all-left-columns-as-value treat all columns except 1th one as value for kv-file with
more than 2 columns
--nr-width int minimum width for {nr}, {gnr}, {enr}, {rnr} in flag
-r/--replacement. e.g., formating "1" to "001" by --nr-width
3 (default 1)
-p, --pattern string search regular expression (default ".*")
-r, --replacement string replacement. supporting capture variables. e.g. $1
represents the text of the first submatch. ATTENTION: for
*nix OS, use SINGLE quote NOT double quotes or use the \
escape character. Record number is also supported by
"{nr}".use ${1} instead of $1 when {kv} given!
-n, --start-num int starting number when using {nr}, {gnr}, {enr}, {rnr} in
replacement (default 1)
Examples
-
remove Chinese charactors
$ csvtk replace -F -f "*_name" -p "\p{Han}+" -r "" -
replace by key-value files
$ cat data.tsv name id A ID001 B ID002 C ID004 $ cat alias.tsv 001 Tom 002 Bob 003 Jim $ csvtk replace -t -f 2 -p "ID(.+)" -r "N: {nr}, alias: {kv}" -k alias.tsv data.tsv [INFO] read key-value file: alias.tsv [INFO] 3 pairs of key-value loaded name id A N: 1, alias: Tom B N: 2, alias: Bob C N: 3, alias
round
Usage
round float to n decimal places
Usage:
csvtk round [flags]
Flags:
-a, --all-fields all fields, overides -f/--fields
-n, --decimal-width int limit floats to N decimal points (default 2)
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for round
Examples:
$ cat testdata/floats.csv | csvtk pretty
a b
0.12345 abc
NA 0.9999198549640733
12.3 e3
1.4814505299984235e-05 -3.1415926E05
# one or more fields
$ cat testdata/floats.csv | csvtk round -n 2 -f b | csvtk pretty
a b
0.12345 abc
NA 1.00
12.3 e3
1.4814505299984235e-05 -3.14E05
# all fields
$ cat testdata/floats.csv | csvtk round -n 2 -a | csvtk pretty
a b
0.12 abc
NA 1.00
12.30 e3
1.48e-05 -3.14E05
sample
Usage
sampling by proportion
Usage:
csvtk sample [flags]
Flags:
-h, --help help for sample
-n, --line-number print line number as the first column ("n")
-p, --proportion float sample by proportion
-s, --rand-seed int rand seed (default 11)
Examples
$ seq 100 | csvtk sample -H -p 0.5 | wc -l
46
$ seq 100 | csvtk sample -H -p 0.5 | wc -l
46
$ seq 100 | csvtk sample -H -p 0.1 | wc -l
10
$ seq 100 | csvtk sample -H -p 0.05 -n
50,50
52,52
65,65
sep
Usage
separate column into multiple columns
Usage:
csvtk sep [flags]
Flags:
--drop drop extra data, exclusive with --merge
-f, --fields string select only these fields. e.g -f 1,2 or -f columnA,columnB (default "1")
-h, --help help for sep
-i, --ignore-case ignore case
--merge only splits at most N times, exclusive with --drop
--na string content for filling NA data
-n, --names strings new column names
-N, --num-cols int preset number of new created columns
-R, --remove remove input column
-s, --sep string separator
-r, --use-regexp separator is a regular expression
Examples:
$ cat players.csv | csvtk collapse -f 1 -v 3 -s ';'
gender,name
male,A;B;C
female,a;b;c;d
# set number of new columns as 3.
$ cat players.csv | csvtk collapse -f 1 -v 3 -s ';' \
| csvtk sep -f 2 -s ';' -n p1,p2,p3,p4 -N 4 --na NA \
| csvtk pretty
gender name p1 p2 p3 p4
------ ------- -- -- -- --
male A;B;C A B C NA
female a;b;c;d a b c d
# set number of new columns as 3, drop extra values
$ cat players.csv | csvtk collapse -f 1 -v 3 -s ';' \
| csvtk sep -f 2 -s ';' -n p1,p2,p3 --drop \
| csvtk pretty
gender name p1 p2 p3
------ ------- -- -- --
male A;B;C A B C
female a;b;c;d a b c
# set number of new columns as 3, split as most 3 parts
$ cat players.csv | csvtk collapse -f 1 -v 3 -s ';' \
| csvtk sep -f 2 -s ';' -n p1,p2,p3 --merge \
| csvtk pretty
gender name p1 p2 p3
------ ------- -- -- ---
male A;B;C A B C
female a;b;c;d a b c;
#
$ echo -ne "taxid\tlineage\n9606\tEukaryota;Chordata;Mammalia;Primates;Hominidae;Homo;Homo sapiens\n"
taxid lineage
9606 Eukaryota;Chordata;Mammalia;Primates;Hominidae;Homo;Homo sapiens
$ echo -ne "taxid\tlineage\n9606\tEukaryota;Chordata;Mammalia;Primates;Hominidae;Homo;Homo sapiens\n" \
| csvtk sep -t -f 2 -s ';' -n kindom,phylum,class,order,family,genus,species --remove \
| csvtk pretty -t
taxid kindom phylum class order family genus species
----- --------- -------- -------- -------- --------- ----- ------------
9606 Eukaryota Chordata Mammalia Primates Hominidae Homo Homo sapiens
sort
Usage
sort by selected fields
Field types:
- Column name : -k name
- Nth field : -k 1
- field range:
- All fields : -k 1-
- From 3rd to 5th column : -k 3-5
- Fields except for the 4th : -k -4
- Fields except for 3rd-5th : -k -3--5
Sort types:
- Default: alphabetical order : -k 1-
- n : numeric order : -k 1:n
- N : natural order : -k 1:N (e.g., "a9" should be in front of "a10")
- d : sort by date : -k 1:d (support multiple formats of date and time)
- u : custom levels : -k 1:u -L levels.txt
Combinations:
- All sort types can be used with "r" for reversing the order, e.g., -k 1:nr
- Multiple fields can be used, e.g., -k year:n -k name
Usage:
csvtk sort [flags]
Flags:
-h, --help help for sort
-i, --ignore-case ignore-case
-k, --keys strings keys (multiple values supported). sort type supported, "N" for natural order,
"n" for number, "d" for date/time, "u" for user-defined order and "r" for
reverse. e.g., "-k 1", "-k 2-", "-k 3-5:nr", "-k A:r", "-k 1:nr -k 2" (default [1-])
-L, --levels strings user-defined level file (one level per line, multiple values supported).
format: <field>:<level-file>. e.g., "-k name:u -L name:level.txt"
Examples
-
data
$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" -
By single column :
csvtk sort -k 1orcsvtk sort -k last_name-
in alphabetical order
$ cat testdata/names.csv \ | csvtk sort -k first_name id,first_name,last_name,username 2,Ken,Thompson,ken 11,Rob,Pike,rob NA,Robert,Abel,123 1,Robert,Thompson,abc 4,Robert,Griesemer,gri -
in reversed alphabetical order (
key:r)$ cat testdata/names.csv \ | csvtk sort -k first_name:r id,first_name,last_name,username NA,Robert,Abel,123 1,Robert,Thompson,abc 4,Robert,Griesemer,gri 11,Rob,Pike,rob 2,Ken,Thompson,ken -
in numerical order (
key:n)$ cat testdata/names.csv \ | csvtk sort -k id:n id,first_name,last_name,username NA,Robert,Abel,123 1,Robert,Thompson,abc 2,Ken,Thompson,ken 4,Robert,Griesemer,gri 11,Rob,Pike,rob -
in natural order (
key:N)$ cat testdata/names.csv | csvtk sort -k id:N id,first_name,last_name,username 1,Robert,Thompson,abc 2,Ken,Thompson,ken 4,Robert,Griesemer,gri 11,Rob,Pike,rob NA,Robert,Abel,123 -
in natural order (
key:N), a bioinformatics example$ echo "X,Y,1,10,2,M,11,1_c,Un_g,1_g" | csvtk transpose X Y 1 10 2 M 11 1_c Un_g 1_g $ echo "X,Y,1,10,2,M,11,1_c,Un_g,1_g" \ | csvtk transpose \ | csvtk sort -H -k 1:N 1 1_c 1_g 2 10 11 M Un_g X Y
-
-
By multiple columns:
csvtk sort -k 1,2orcsvtk sort -k 1 -k 2orcsvtk sort -k last_name,age# by first_name and then last_name $ cat testdata/names.csv | csvtk sort -k first_name -k last_name id,first_name,last_name,username 2,Ken,Thompson,ken 11,Rob,Pike,rob NA,Robert,Abel,123 4,Robert,Griesemer,gri 1,Robert,Thompson,abc # by first_name and then ID $ cat testdata/names.csv | csvtk sort -k first_name -k id:n id,first_name,last_name,username 2,Ken,Thompson,ken 11,Rob,Pike,rob NA,Robert,Abel,123 1,Robert,Thompson,abc 4,Robert,Griesemer,gri -
By a range of columns:
csvtk sort -k 1-,csvtk sort -k 3-5,csvtk sort -k -3--5.$ csvtk pretty testdata/digitals2.csv f1 f2 f3 f4 f5 --- ---- ---- --- --- foo bar xyz 1 0
foo bar2 xyz 1.5 -1 foo bar2 xyz 3 2
foo bar xyz 5 3
foo bar2 xyz N/A 4
bar xyz abc NA 2
bar xyz abc2 1 -1 bar xyz abc 2 0
bar xyz abc 1 5
bar xyz abc 3 100 bar xyz2 abc3 2 3
bar xyz2 abc3 2 1$ csvtk sort testdata/digitals2.csv -k 1-3:N -k 4:n | csvtk pretty f1 f2 f3 f4 f5 --- ---- ---- --- --- bar xyz abc 1 5
bar xyz abc 2 0
bar xyz abc 3 100 bar xyz abc NA 2
bar xyz abc2 1 -1 bar xyz2 abc3 2 3
bar xyz2 abc3 2 1
foo bar xyz 1 0
foo bar xyz 5 3
foo bar2 xyz 1.5 -1 foo bar2 xyz 3 2
foo bar2 xyz N/A 4 -
By user-defined order
# user-defined order/level $ cat testdata/size_level.txt tiny mini small medium big # original data $ cat testdata/size.csv id,size 1,Huge 2,Tiny 3,Big 4,Small 5,Medium $ csvtk sort -k 2:u -i -L 2:testdata/size_level.txt testdata/size.csv id,size 2,Tiny 4,Small 5,Medium 3,Big 1,Huge -
By date
$ csvtk pretty testdata/datesub.csv ID Name In Out
-- ----- ------------------- ------------------- 1 Tom 2023-08-25 11:24:00 2023-08-27 08:33:02 2 Sally 2023-08-25 11:28:00 2023-08-26 14:17:35 3 Alf 2023-08-26 11:29:00 2023-08-29 20:43:00$ cat testdata/datesub.csv | csvtk sort -k In:d -k Out:dr | csvtk pretty ID Name In Out
-- ----- ------------------- ------------------- 1 Tom 2023-08-25 11:24:00 2023-08-27 08:33:02 2 Sally 2023-08-25 11:28:00 2023-08-26 14:17:35 3 Alf 2023-08-26 11:29:00 2023-08-29 20:43:00$ csvtk pretty testdata/date3.csv day id ------- --- Oct. 1 a10 Jul. 14 b1 Jun. 12 a9 Jul. 4 b2 Dec. 25 b11
$ cat testdata/date3.csv | csvtk sort -k 1:d | csvtk pretty day id ------- --- Jun. 12 a9 Jul. 4 b2 Jul. 14 b1 Oct. 1 a10 Dec. 25 b11
shuf
Usage
shuffle rows
Usage:
csvtk shuf [flags]
Flags:
-h, --help help for shuf
-s, --rand-seed int rand seed (default 11)
-n, --rows int print first N rows, 0 for all
Examples:
-
Default
$ csvtk shuf testdata/names.csv | csvtk pretty id first_name last_name username -- ---------- --------- -------- NA Robert Abel 123 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc 11 Rob Pike rob -
Change order with a different random seed.
$ csvtk shuf testdata/names.csv -s 1 | csvtk pretty id first_name last_name username -- ---------- --------- -------- 4 Robert Griesemer gri 11 Rob Pike rob 2 Ken Thompson ken NA Robert Abel 123 1 Robert Thompson abc -
Only print the first N rows.
$ csvtk shuf testdata/names.csv -n 1 | csvtk pretty id first_name last_name username -- ---------- --------- -------- NA Robert Abel 123
space2tab
Usage
convert space delimited format to TSV
Usage:
csvtk space2tab [flags]
Flags:
-b, --buffer-size string size of buffer, supported unit: K, M, G. You need increase the value when
"bufio.Scanner: token too long" error reported (default "1G")
-h, --help help for space2tab
Exapmles
$ echo a b | csvtk space2tab
a b
split
Usage
split CSV/TSV into multiple files according to column values
Notes:
1. flag -o/--out-file can specify out directory for splitted files.
2. flag -s/--prefix-as-subdir can create subdirectories with prefixes of
keys of length X, to avoid writing too many files in the output directory.
Usage:
csvtk split [flags]
Flags:
-g, --buf-groups int buffering N groups before writing to file (default 100)
-b, --buf-rows int buffering N rows for every group before writing to file (default 100000)
-f, --fields string comma separated key fields, column name or index. e.g. -f 1-3 or -f
id,id2 or -F -f "group*" (default "1")
--force overwrite existing output directory (given by -o).
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for split
-i, --ignore-case ignore case
-G, --out-gzip force output gzipped file
-p, --out-prefix string output file prefix, the default value is the input file. use -p "" to
disable outputting prefix
-s, --prefix-as-subdir int create subdirectories with prefixes of keys of length X, to avoid writing
too many files in the output directory
Examples
-
Test data
$ cat names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" -
split according to
first_name$ csvtk split names.csv -f first_name $ ls *.csv names.csv names-Ken.csv names-Rob.csv names-Robert.csv $ cat names-Ken.csv id,first_name,last_name,username 2,Ken,Thompson,ken $ cat names-Rob.csv id,first_name,last_name,username 11,Rob,Pike,rob $ cat names-Robert.csv id,first_name,last_name,username 4,Robert,Griesemer,gri 1,Robert,Thompson,abc NA,Robert,Abel,123 -
split according to
first_nameandlast_name$ csvtk split names.csv -f first_name,last_name $ ls *.csv names.csv names-Robert-Abel.csv names-Robert-Thompson.csv names-Ken-Thompson.csv names-Robert-Griesemer.csv names-Rob-Pike.csv -
flag
-o/--out-filecan specify out directory for splitted files$ seq 10000 | csvtk split -H -o result $ ls result/*.csv | wc -l 10000 -
Do not output prefix, use
-p "".$ echo -ne "1,ACGT\n2,GGCA\n3,ACAAC\n" 1,ACGT 2,GGCA 3,ACAAC $ echo -ne "1,ACGT\n2,GGCA\n3,ACAAC\n" | csvtk split -H -f 2 -o t -p "" -s 3 --force $ tree t t ├── ACA │ └── ACAAC.csv ├── ACG │ └── ACGT.csv └── GGC └── GGCA.csv 4 directories, 3 files -
extreme example 1: lots (1M) of rows in groups
$ yes 2 | head -n 10000000 | gzip -c > t.gz $ memusg -t csvtk -H split t.gz elapsed time: 5.859s peak rss: 41.45 MB # check $ zcat t-2.gz | wc -l 10000000 $ zcat t-2.gz | md5sum f194afd7cecf645c0e3cce50c9bc526e - $ zcat t.gz | md5sum f194afd7cecf645c0e3cce50c9bc526e - -
extreme example 2: lots (10K) of groups
$ seq 10000 | gzip -c > t2.gz $ memusg -t csvtk -H split t2.gz -o t2 elapsed time: 20.856s peak rss: 23.77 MB # check $ ls t2/*.gz | wc -l 10000 $ zcat t2/*.gz | sort -k 1,1n | md5sum 72d4ff27a28afbc066d5804999d5a504 - $ zcat t2.gz | md5sum 72d4ff27a28afbc066d5804999d5a504 -since, v0.31.0, the flag
-s/--prefix-as-subdircan create subdirectories with prefixes of keys of length X, to avoid writing too many files in the output directory.$ memusg -t csvtk -H split t2.gz -o t2 -s 3 elapsed time: 2.668s peak rss: 1.79 GB$ fd .gz$ t2 | rush 'zcat {}' | sort -k 1,1n | md5sum 72d4ff27a28afbc066d5804999d5a504 -
$ tree t2/ | more t2/ ├── 100 │ ├── t2-10000.gz │ ├── t2-1000.gz │ ├── t2-1001.gz │ ├── t2-1002.gz │ ├── t2-1003.gz │ ├── t2-1004.gz │ ├── t2-1005.gz │ ├── t2-1006.gz │ ├── t2-1007.gz │ ├── t2-1008.gz │ └── t2-1009.gz ├── 101 │ ├── t2-1010.gz │ ├── t2-1011.gz ... ├── t2-994.gz ├── t2-995.gz ├── t2-996.gz ├── t2-997.gz ├── t2-998.gz ├── t2-999.gz ├── t2-99.gz └── t2-9.gz 901 directories, 10000 files
splitxlsx
Usage
split XLSX sheet into multiple sheets according to column values
Strengths: Sheet properties are remained unchanged.
Weakness : Complicated sheet structures are not well supported, e.g.,
1. merged cells
2. more than one header row
Usage:
csvtk splitxlsx [flags]
Flags:
-f, --fields string comma separated key fields, column name or index. e.g. -f 1-3 or -f id,id2
or -F -f "group*" (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for splitxlsx
-i, --ignore-case ignore case (cell value)
-a, --list-sheets list all sheets
-N, --sheet-index int Nth sheet to retrieve (default 1)
-n, --sheet-name string sheet to retrieve
Examples
-
example data
# list all sheets $ csvtk xlsx2csv -a accounts.xlsx index sheet 1 names 2 phones 3 region # data of sheet "names" $ csvtk xlsx2csv accounts.xlsx | csvtk pretty id first_name last_name username 11 Rob Pike rob 2 Ken Thompson ken 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123 -
split sheet "names" according to
first_name$ csvtk splitxlsx accounts.xlsx -n names -f first_name $ ls accounts.* accounts.split.xlsx accounts.xlsx $ csvtk splitxlsx -a accounts.split.xlsx index sheet 1 names 2 phones 3 region 4 Rob 5 Ken 6 Robert $ csvtk xlsx2csv accounts.split.xlsx -n Rob \ | csvtk pretty id first_name last_name username 11 Rob Pike rob $ csvtk xlsx2csv accounts.split.xlsx -n Robert \ | csvtk pretty id first_name last_name username 4 Robert Griesemer gri 1 Robert Thompson abc NA Robert Abel 123
spread
Usage
spread a key-value pair across multiple columns, like tidyr::spread/pivot_wider
Usage:
csvtk spread [flags]
Aliases:
spread, wider, scatter
Flags:
-h, --help help for spread
-k, --key string field of the key. e.g -k 1 or -k columnA
--na string content for filling NA data
-s, --separater string separater for values that share the same key (default "; ")
-v, --value string field of the value. e.g -v 1 or -v columnA
Examples:
Shuffled columns:
$ csvtk cut -f 1,4,2,3 testdata/names.csv \
| csvtk pretty -S simple
----------------------------------------
id username first_name last_name
----------------------------------------
11 rob Rob Pike
2 ken Ken Thompson
4 gri Robert Griesemer
1 abc Robert Thompson
NA 123 Robert Abel
----------------------------------------
data -> gather/longer -> spread/wider. Note that the orders of both rows and columns are kept :)
$ csvtk cut -f 1,4,2,3 testdata/names.csv \
| csvtk gather -k item -v value -f -1 \
| csvtk spread -k item -v value \
| csvtk pretty -S simple
----------------------------------------
id username first_name last_name
----------------------------------------
11 rob Rob Pike
2 ken Ken Thompson
4 gri Robert Griesemer
1 abc Robert Thompson
NA 123 Robert Abel
----------------------------------------
No header rows
$ echo -ne "a,a,0\nb,b,0\nc,c,0\na,b,1\na,c,2\nb,c,3\n"
a,a,0
b,b,0
c,c,0
a,b,1
a,c,2
b,c,3
$ echo -ne "a,a,0\nb,b,0\nc,c,0\na,b,1\na,c,2\nb,c,3\n" \
| csvtk spread -H -k 2 -v 3 \
| csvtk pretty -S bold
┏━━━┳━━━┳━━━┳━━━┓
┃ ┃ a ┃ b ┃ c ┃
┣━━━╋━━━╋━━━╋━━━┫
┃ a ┃ 0 ┃ 1 ┃ 2 ┃
┣━━━╋━━━╋━━━╋━━━┫
┃ b ┃ ┃ 0 ┃ 3 ┃
┣━━━╋━━━╋━━━╋━━━┫
┃ c ┃ ┃ ┃ 0 ┃
┗━━━┻━━━┻━━━┻━━━┛
summary
Usage
summary statistics of selected numeric or text fields (groupby group fields)
Attention:
1. Do not mix use field (column) numbers and names.
2. Field range is supported, e.g., "-f 2-5:sum".
Available operations:
# numeric/statistical operations
# provided by github.com/gonum/stat and github.com/gonum/floats
countn (count numeric values), min, max, sum, argmin, argmax,
mean, stdev, variance, median, q1, q2, q3,
entropy (Shannon entropy),
prod (product of the elements)
# textual/numeric operations
count, first, last, rand, unique/uniq, collapse, countunique
Usage:
csvtk summary [flags]
Flags:
-w, --decimal-width int limit floats to N decimal points (default 2)
-f, --fields strings operations on these fields. e.g "-f 1:count,1:sum", "-f 2-5:sum", or "-f
colA:mean". available operations: argmax, argmin, collapse, count, countn,
countuniq, countunique, entropy, first, last, max, mean, median, min, prod,
q1, q2, q3, rand, stdev, sum, uniq, unique, variance
-g, --groups string group via fields. e.g -g 1,2 or -g columnA,columnB
-h, --help help for summary
-i, --ignore-non-numbers ignore non-numeric values like "NA" or "N/A"
-S, --rand-seed int rand seed for operation "rand" (default 11)
-s, --separater string separater for collapsed data (default "; ")
Examples
-
data
$ cat testdata/digitals2.csv f1,f2,f3,f4,f5 foo,bar,xyz,1,0 foo,bar2,xyz,1.5,-1 foo,bar2,xyz,3,2 foo,bar,xyz,5,3 foo,bar2,xyz,N/A,4 bar,xyz,abc,NA,2 bar,xyz,abc2,1,-1 bar,xyz,abc,2,0 bar,xyz,abc,1,5 bar,xyz,abc,3,100 bar,xyz2,abc3,2,3 bar,xyz2,abc3,2,1 -
use flag
-i/--ignore-non-numbers$ cat testdata/digitals2.csv \ | csvtk summary -f f4:sum [ERRO] column 4 has non-digital data: N/A, you can use flag -i/--ignore-non-numbers to skip these data $ cat testdata/digitals2.csv \ | csvtk summary -f f4:sum -i f4:sum 21.50 -
multiple fields suported
$ cat testdata/digitals2.csv \ | csvtk summary -f f4:sum,f5:sum -i f4:sum,f5:sum 21.50,118.00 -
using fields instead of colname is still supported
$ cat testdata/digitals2.csv \ | csvtk summary -f 4:sum,5:sum -i f4:sum,f5:sum 21.50,118.00and the field range is supported.
$ cat testdata/digitals2.csv \ | csvtk summary -f 4-5:sum -i f4:sum,f5:sum 21.50,118.00 -
but remember do not mix use column numbers and names
$ cat testdata/digitals2.csv \ | csvtk summary -f f4:sum,5:sum -i [ERRO] column "5" not existed in file: - $ cat testdata/digitals2.csv \ | csvtk summary -f 4:sum,f5:sum -i [ERRO] failed to parse f5 as a field number, you may mix the use of field numbers and column names -
groupby
$ cat testdata/digitals2.csv \ | csvtk summary -i -f f4:sum,f5:sum -g f1,f2 \ | csvtk pretty f1 f2 f4:sum f5:sum --- ---- ------ ------ bar xyz 7.00 106.00 bar xyz2 4.00 4.00 foo bar 6.00 3.00 foo bar2 4.50 5.00 -
for data without header line
$ cat testdata/digitals2.csv | sed 1d \ | csvtk summary -H -i -f 4:sum,5:sum -g 1,2 \ | csvtk pretty -H bar xyz 7.00 106.00 bar xyz2 4.00 4.00 foo bar 6.00 3.00 foo bar2 4.50 5.00 -
numeric/statistical operations
$ cat testdata/digitals2.csv \ | csvtk summary -i -g f1 -f f4:countn,f4:mean,f4:stdev,f4:q1,f4:q2,f4:mean,f4:q3,f4:min,f4:max \ | csvtk pretty f1 f4:countn f4:mean f4:stdev f4:q1 f4:q2 f4:mean f4:q3 f4:min f4:max --- --------- ------- -------- ----- ----- ------- ----- ------ ------ bar 6 1.83 0.75 1.25 2.00 1.83 2.00 1.00 3.00 foo 4 2.62 1.80 1.38 2.25 2.62 3.50 1.00 5.00 -
textual/numeric operations
$ cat testdata/digitals2.csv \ | csvtk summary -i -g f1 -f f2:count,f2:first,f2:last,f2:rand,f2:collapse,f2:uniq,f2:countunique \ | csvtk pretty f1 f2:count f2:first f2:last f2:rand f2:collapse f2:uniq f2:countunique --- -------- -------- ------- ------- ----------------------------------- --------- -------------- bar 7 xyz xyz2 xyz2 xyz; xyz; xyz; xyz; xyz; xyz2; xyz2 xyz; xyz2 2 foo 5 bar bar2 bar2 bar; bar2; bar2; bar; bar2 bar2; bar -
mixed operations
$ cat testdata/digitals2.csv \ | csvtk summary -i -g f1 -f f4:collapse,f4:max \ | csvtk pretty f1 f4:collapse f4:max --- -------------------- ------ bar NA; 1; 2; 1; 3; 2; 2 3.00 foo 1; 1.5; 3; 5; N/A 5.00 -
countandcountn(count of digits)$ cat testdata/digitals2.csv \ | csvtk summary -f f4:count,f4:countn -i \ | csvtk pretty f4:count f4:countn -------- --------- 12 10 # details: $ cat testdata/digitals2.csv \ | csvtk summary -f f4:count,f4:countn,f4:collapse -i -g f1 \ | csvtk pretty f1 f4:count f4:countn f4:collapse --- -------- --------- -------------------- bar 7 6 NA; 1; 2; 1; 3; 2; 2 foo 5 4 1; 1.5; 3; 5; N/A
tab2csv
Usage
convert tabular format to CSV
Usage:
csvtk tab2csv [flags]
Flags:
-h, --help help for tab2csv
Example
$ echo -e "a\tb\tc" | csvtk tab2csv
a,b,c
transpose
Usage
transpose CSV data
Usage:
csvtk transpose [flags]
Examples
$ cat testdata/digitals.tsv
4 5 6
1 2 3
7 8 0
8 1,000 4
$ csvtk transpose -t testdata/digitals.tsv
4 1 7 8
5 2 8 1,000
6 3 0 4
unfold
Usage
unfold multiple values in cells of a field
Example:
$ echo -ne "id,values,meta\n1,a;b,12\n2,c,23\n3,d;e;f,34\n" \
| csvtk pretty
id values meta
1 a;b 12
2 c 23
3 d;e;f 34
$ echo -ne "id,values,meta\n1,a;b,12\n2,c,23\n3,d;e;f,34\n" \
| csvtk unfold -f values -s ";" \
| csvtk pretty
id values meta
1 a 12
1 b 12
2 c 23
3 d 34
3 e 34
3 f 34
Usage:
csvtk unfold [flags]
Flags:
-f, --fields string field to expand, only one field is allowed. type "csvtk unfold -h" for examples
-h, --help help for unfold
-s, --separater string separater for folded values (default "; ")
uniq
Usage
unique data without sorting
Usage:
csvtk uniq [flags]
Flags:
-f, --fields string select these fields as keys. e.g -f 1,2 or -f columnA,columnB (default "1")
-F, --fuzzy-fields using fuzzy fields, e.g., -F -f "*name" or -F -f "id123*"
-h, --help help for uniq
-i, --ignore-case ignore case
-n, --keep-n int keep at most N records for a key (default 1)
Examples:
-
data:
$ cat testdata/names.csv id,first_name,last_name,username 11,"Rob","Pike",rob 2,Ken,Thompson,ken 4,"Robert","Griesemer","gri" 1,"Robert","Thompson","abc" NA,"Robert","Abel","123" -
unique first_name (it removes rows with duplicated first_name)
$ cat testdata/names.csv \ | csvtk uniq -f first_name id,first_name,last_name,username 11,Rob,Pike,rob 2,Ken,Thompson,ken 4,Robert,Griesemer,gri -
unique first_name, a more common way
$ cat testdata/names.csv \ | csvtk cut -f first_name \ | csvtk uniq -f 1 first_name Rob Ken Robert -
keep top 2 items for every group.
$ cat testdata/players.csv gender,id,name male,1,A male,2,B male,3,C female,11,a female,12,b female,13,c female,14,d $ cat testdata/players.csv \ | csvtk sort -k gender:N -k id:nr \ | csvtk uniq -f gender -n 2 gender,id,name female,14,d female,13,c male,3,C male,2,B
version
Usage
$ csvtk version -h
print version information and check for update
Usage:
csvtk version [flags]
Flags:
-u, --check-update check update
-h, --help help for version
watch
Usage
monitor the specified fields
Usage:
csvtk watch [flags]
Flags:
-B, --bins int number of histogram bins (default -1)
-W, --delay int sleep this many seconds after plotting (default 1)
-y, --dump print histogram data to stderr instead of plotting
-f, --field string field to watch
-h, --help help for watch
-O, --image string save histogram to this PDF/image file
-L, --log log10(x+1) transform numeric values
-x, --pass passthrough mode (forward input to output)
-p, --print-freq int print/report after this many records (-1 for print after EOF) (default -1)
-Q, --quiet supress all plotting to stderr
-R, --reset reset histogram after every report
Examples
-
Read whole file, plot histogram of field on the terminal and PDF
csvtk -t watch -O hist.pdf -f MyField input.tsv -
Monitor a TSV stream, print histogram every 1000 records
cat input.tsv | csvtk -t watch -f MyField -p 1000 - -
Monitor a TSV stream, print histogram every 1000 records, hang forever for updates
tail -f +0 input.tsv | csvtk -t watch -f MyField -p 1000 -
xlsx2csv
Usage
convert XLSX to CSV format
Usage:
csvtk xlsx2csv [flags]
Flags:
-h, --help help for xlsx2csv
-a, --list-sheets list all sheets
-i, --sheet-index int Nth sheet to retrieve (default 1)
-n, --sheet-name string sheet to retrieve
Examples
-
list all sheets
$ csvtk xlsx2csv ../testdata/accounts.xlsx -a index sheet 1 names 2 phones 3 region -
retrieve sheet by index
$ csvtk xlsx2csv ../testdata/accounts.xlsx -i 3 name,region ken,nowhere gri,somewhere shenwei,another Thompson,there -
retrieve sheet by name
$ csvtk xlsx2sv ../testdata/accounts.xlsx -n region name,region ken,nowhere gri,somewhere shenwei,another Thompson,there